Hamamah S., Amin A., Ievoli C., et al. "Gut Microbiome and Bile Acid Changes after Male Rodent Sleeve Gastrectomy: What Comes First?" American Journal of Physiology — Regulatory, Integrative and Comparative Physiology (2025). https://doi.org/10.1152/ajpregu.00297.2024
Research Question
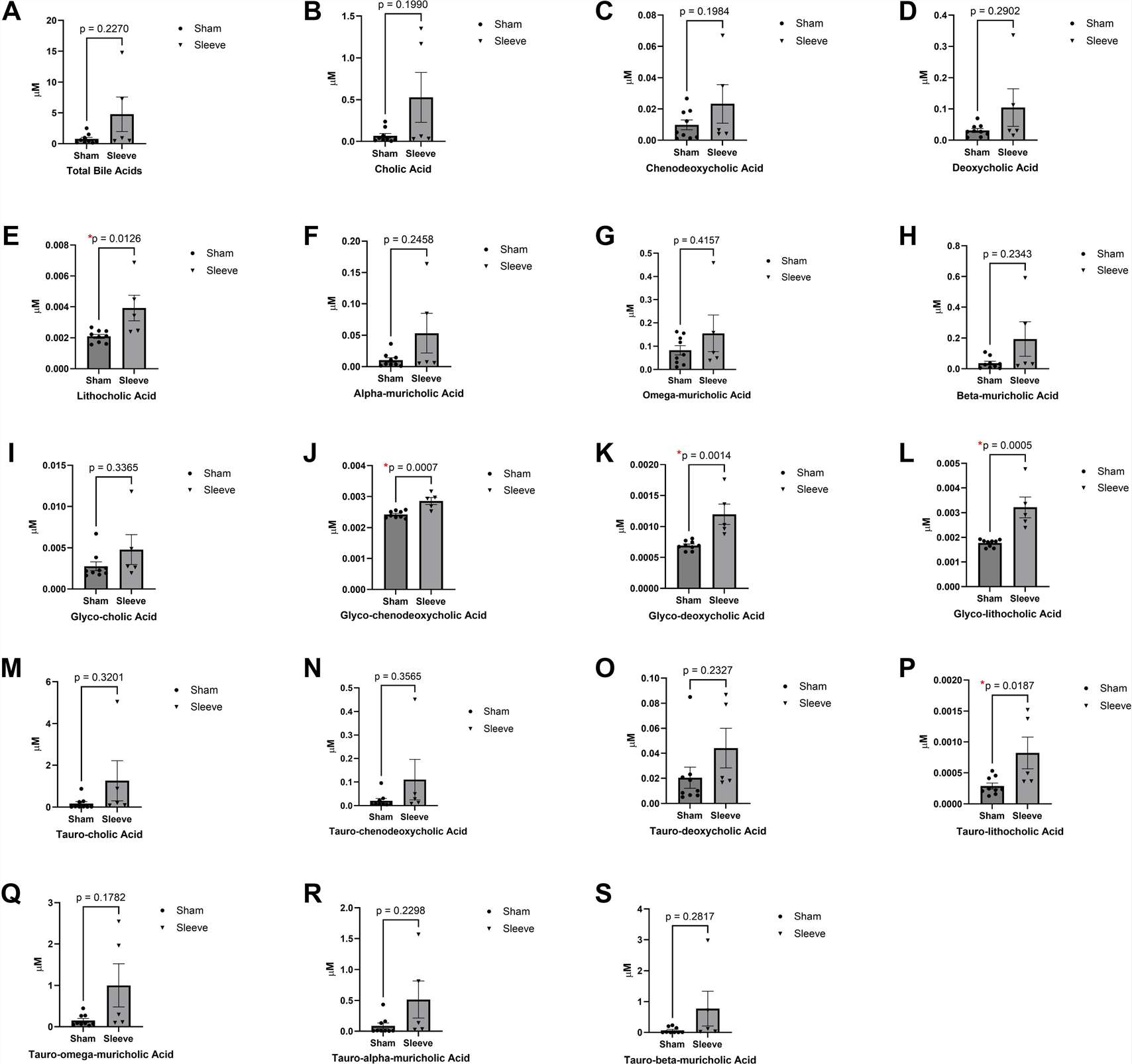
Sleeve gastrectomy (SG) produces metabolic benefits — including reduced weight gain, improved glucose homeostasis, and altered lipid metabolism — that cannot be attributed to caloric restriction alone. The mechanistic sequence linking SG to these outcomes involves both the gut microbiome and the hepatic bile acid (BA) synthetic programme, but the causal directionality had not been established: does SG first alter the microbiome, which then expands the BA pool, or does hepatic BA synthesis change independently of microbiome remodelling? Resolving this required quantitative measurement of individual bile acid species across biological compartments — a question that total BA assays cannot answer.
Methods
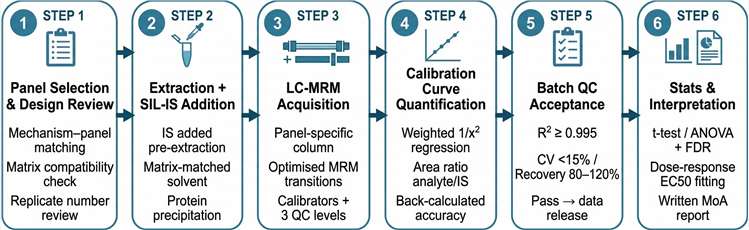
Male C57BL/6J mice underwent sleeve gastrectomy or sham surgery. Fecal material transfer (FMT) experiments were conducted from SG or sham donors to surgically naïve recipients with an intact microbiome, separating microbiome-dependent from surgery-direct effects on the BA pool. Creative Proteomics provided bile acid mass spectrometry and quantitative analysis — a targeted metabolomics panel approach measuring individual conjugated and unconjugated bile acid species in plasma and relevant tissue compartments. Gut microbiome composition was characterised by 16S rRNA amplicon and metagenomic sequencing. Hepatic expression of key BA synthesis and transport genes (slc10a1, cyp8b1) was quantified by qPCR.
Key Findings
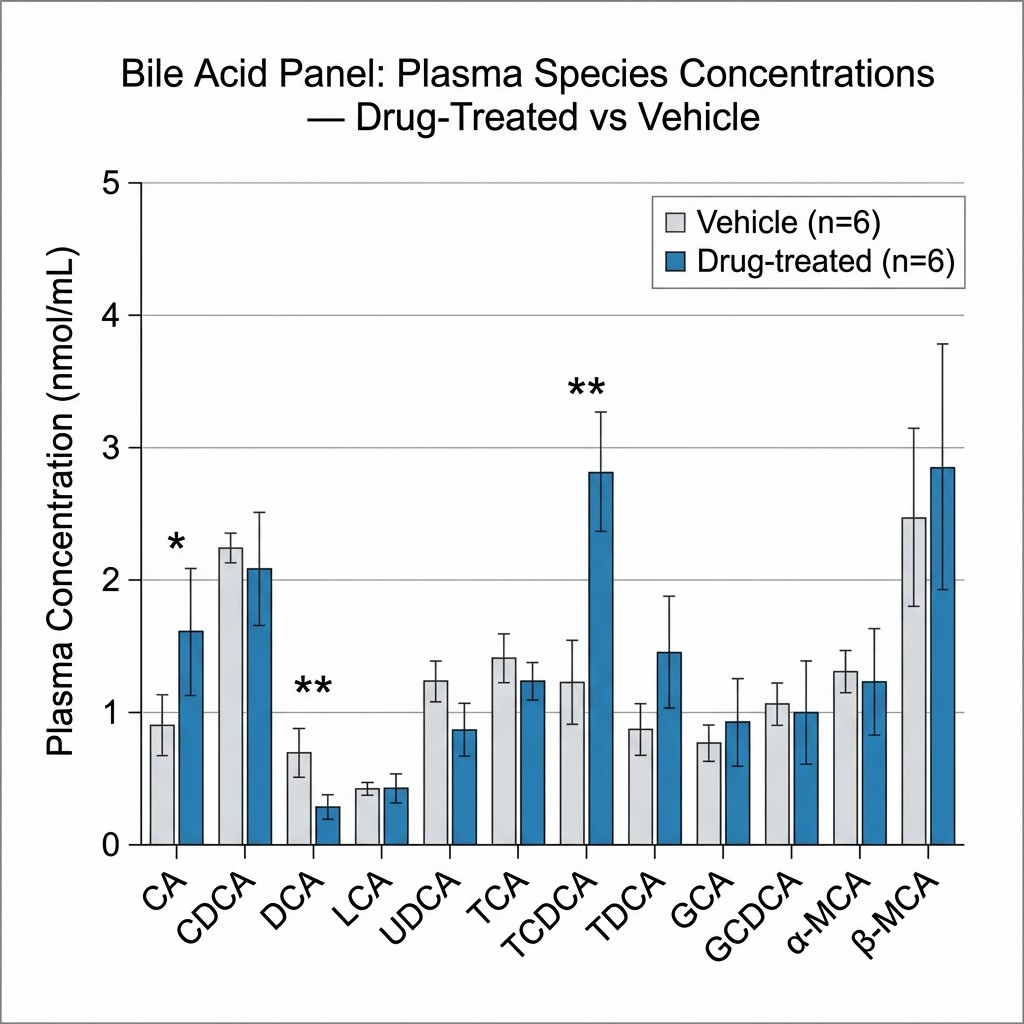
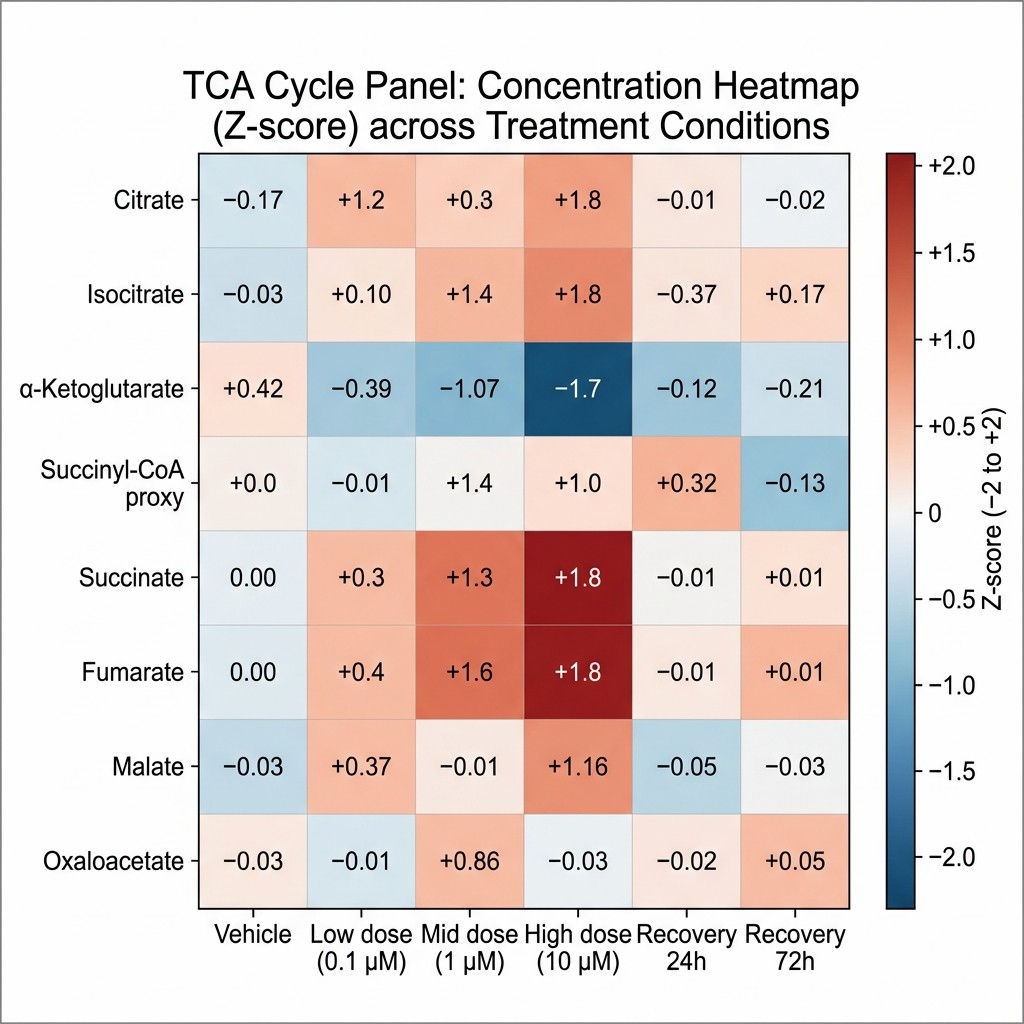
SG significantly deflected weight gain compared with sham surgery: 5 ± 2 g versus 10 ± 3 g at the study endpoint (p = 0.004). The targeted bile acid panel demonstrated that SG significantly increased the total BA pool. Hepatic transcription of slc10a1 — the sodium-taurocholate cotransporting polypeptide responsible for BA reuptake from portal circulation — was reduced after SG (p = 0.04), as was cyp8b1 (p = 0.03), the enzyme controlling the ratio of cholic acid to chenodeoxycholic acid-derived species in the primary BA pool. Random forest analysis of the metagenomic dataset identified Lactobacillus as among the taxa with significantly increased relative abundance in SG versus sham mice. Critically, FMT from SG donors to naïve recipients reproduced elements of the BA pool expansion, supporting a causal role for microbiome remodelling in the BA response — but the hepatic gene expression changes preceded microbiome-dependent effects, suggesting SG initiates BA pool expansion through a direct liver mechanism before the microbiome adapts.
Significance for Targeted Metabolomics Panel Services
This study demonstrates why species-level targeted BA quantification is essential for mechanistic studies involving the gut–liver axis. Total bile acid measurements would have confirmed that the BA pool increased after SG but could not have resolved whether the increase was in primary or secondary species, conjugated or unconjugated forms, or which specific enzymatic steps (cyp8b1, slc10a1) were responsible. The targeted panel data provided the molecular resolution that connected hepatic gene expression changes to specific BA species shifts — mechanistic evidence that informed the causal sequence between surgery, liver enzyme activity, and microbiome adaptation. This precision is what targeted panel screening delivers across any metabolic pathway interrogated in drug discovery or pharmacological mechanism research.