AI-Driven Multi-Omics Integration for Drug Discovery — Proteomics, Metabolomics & Lipidomics
Accelerate drug discovery decisions with integrated multi-omics evidence and AI-powered data analysis.
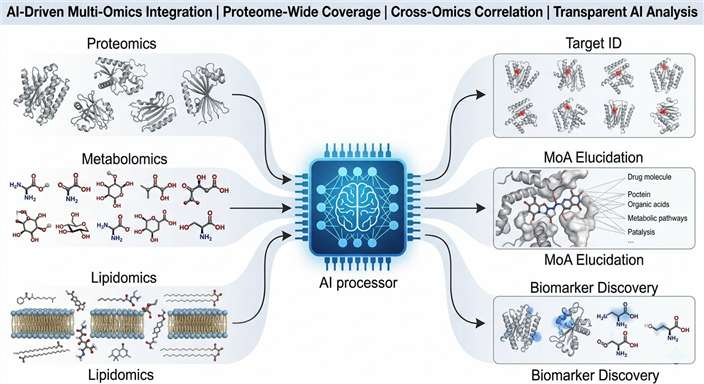
Our platform combines high-resolution mass spectrometry-based proteomics, metabolomics, and lipidomics with advanced bioinformatics to deliver actionable mechanistic insights — from target identification to mechanism-of-action elucidation.
Roughly 90% of drug candidates fail in clinical development, with poor target selection and incomplete mechanism-of-action understanding cited among the leading causes. When proteomics, metabolomics, and lipidomics data are generated in isolation, critical cross-omics relationships remain hidden, and the biological signal needed to make confident go/no-go decisions is fragmented across disconnected datasets.
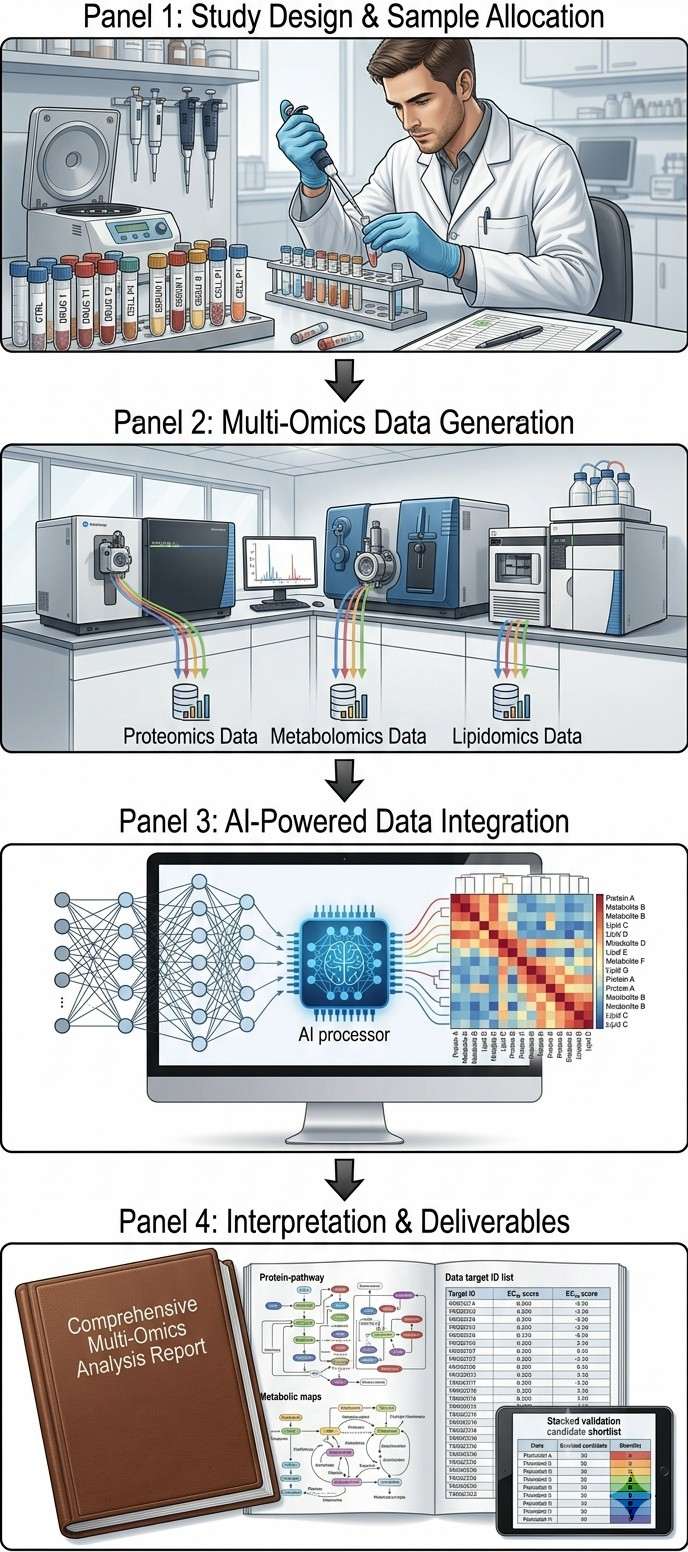
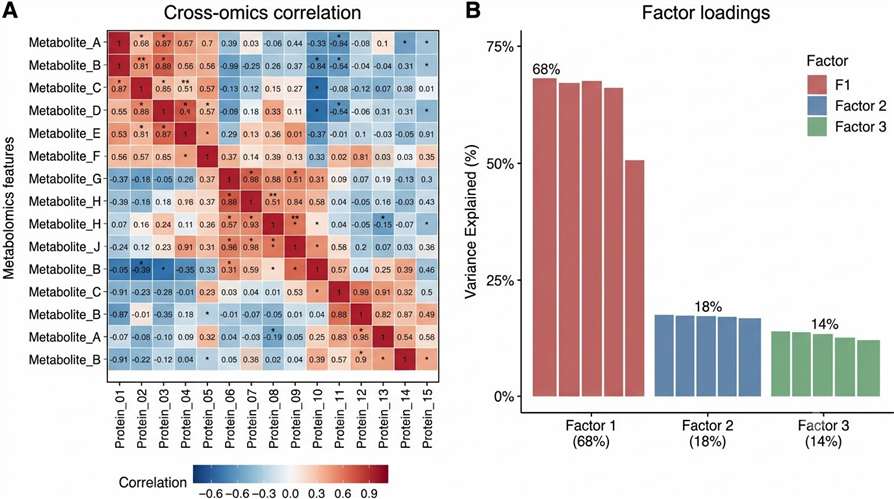
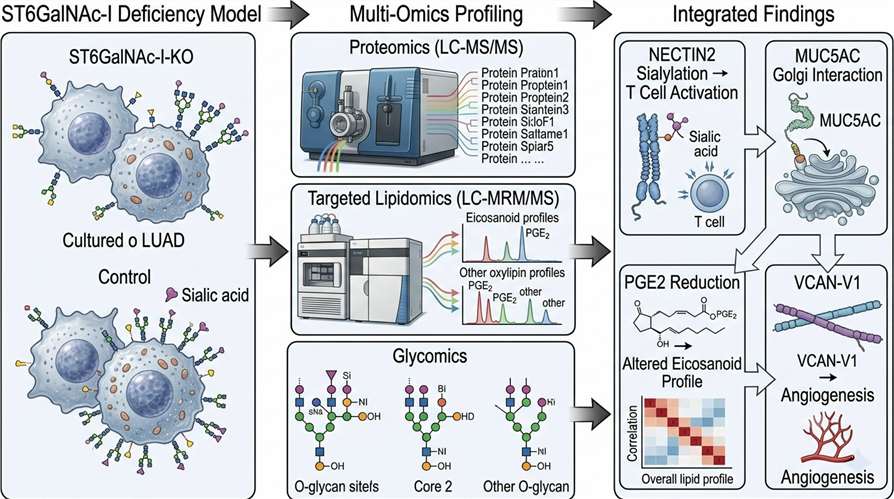
At Creative Proteomics, our AI-driven multi-omics integration service is designed to solve this problem: we produce and integrate orthogonal omics data layers from the same biological samples, apply transparent computational methods to reveal cross-omics correlations, and deliver interpretable results that directly support drug discovery decisions.