From Disease Biology to Validated Targets — A Unified Workflow
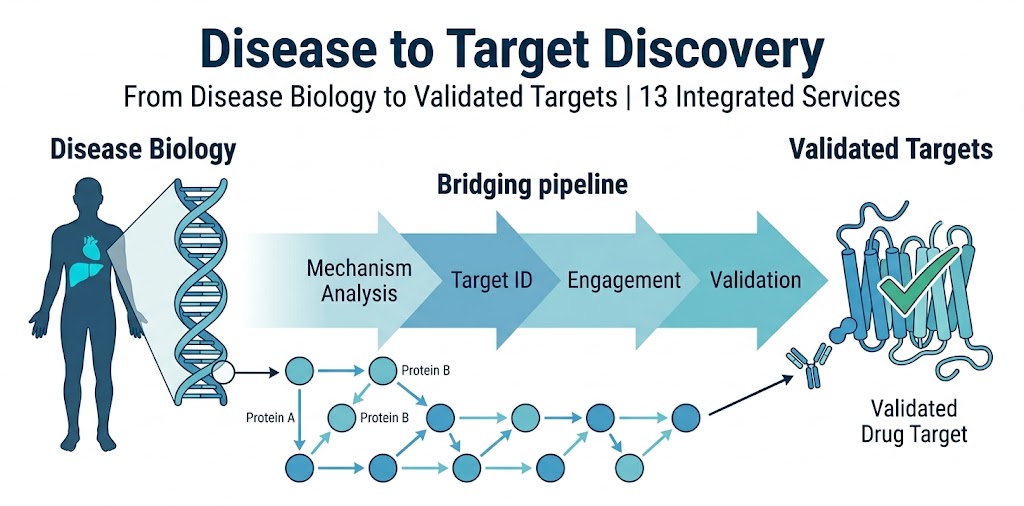
The gap between understanding a disease mechanism and having a validated drug target is where most discovery programs lose momentum. Disease biology research generates hypotheses — differentially expressed proteins, altered pathways, candidate biomarkers — but translating those findings into a high-confidence target list requires an integrated experimental workflow that connects each step from mechanism to validation.
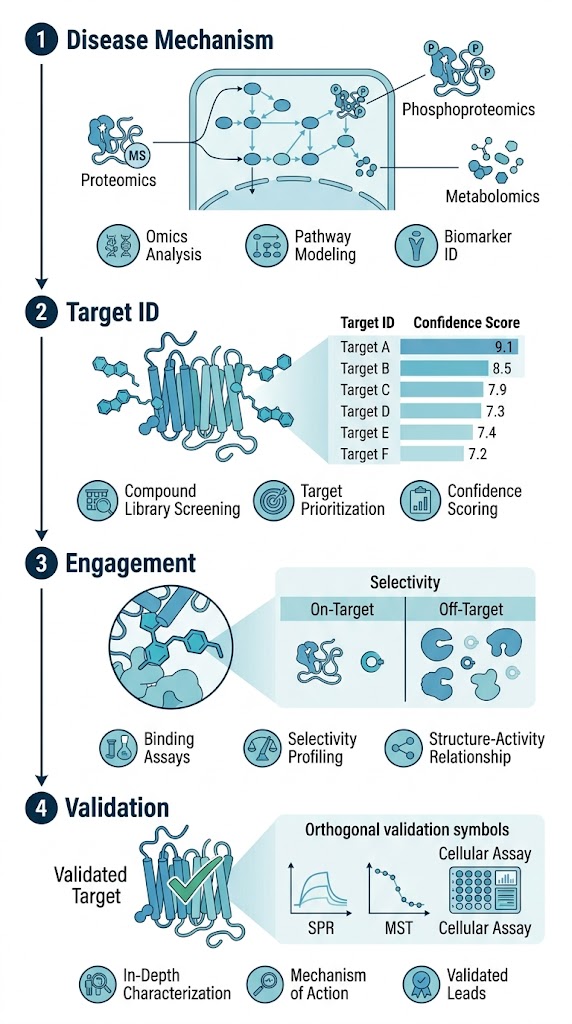
Our Disease → Target Discovery platform provides that connection. We offer 13 integrated sub-services that span the entire target discovery pipeline: from disease mechanism analysis and pathway mapping through proteomics-based target identification, interactome and network analysis, target engagement profiling, and functional validation. The pipeline is designed so that data from each stage feeds directly into the next, with consistent analytical standards, unified bioinformatics pipelines, and coordinated project management across all modules. Whether your compound is a conventional small molecule, a PROTAC degrader, a molecular glue, or a biologic, the platform accommodates the specific characterization requirements of each modality at every stage of the workflow.
Whether your program starts with a clinical observation that needs mechanistic explanation, a phenotypic screen that needs target deconvolution, or a known pathway that needs expanded target discovery, our platform adapts to your entry point. The modular structure means you can engage a single sub-service for a specific question or deploy the full pipeline for comprehensive end-to-end target discovery.
Each of the 13 sub-services is staffed by scientists with domain expertise in the relevant techniques — proteomics, chemical biology, biophysics, cell biology — and supported by a centralized bioinformatics team that ensures data harmonization across modules. This structure means that a project starting with disease pathway analysis can flow seamlessly into target identification, engagement profiling, and validation without re-negotiating data formats, quality standards, or deliverable expectations at each transition point.