In MS-based metabolomics, the starting point of data processing is a collection of raw data files, each file corresponding to a single biological sample. A LC-MS data file is a set of sequentially recorded histograms, each representing hits of ionized molecules on the detector during a very small time frame. A histogram is made up of a number of m/z and intensity data points. The basic purpose of data processing is to transform raw data files into representation that assists easy access to characteristics of each observed ion. The characteristics include retention and m/z time of the ion and an ion intensity measurement from each raw data file. Except for these basic features, data processing can also extract additional information such as isotope distribution of the ion.
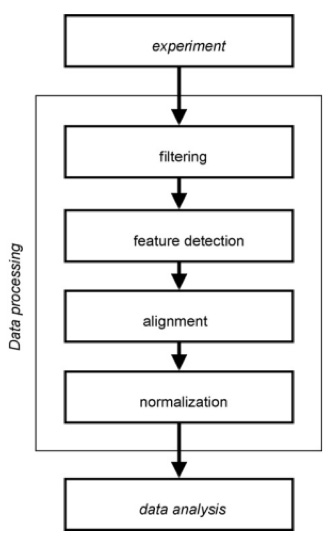
Since different instrument vendors use different proprietary data formats, a preliminary step for data processing required software that is compatible for analyzing metabolomic data from different vendors, enabling conversion of these raw proprietary data into common raw data format such as netCDFor mzXML. Converters to more recent mzXML format have been developed both by research groups and companies. Typical data processing pipeline generally proceeds through multiple stages including filtering, feature detection, alignment and normalization. Raw data are processed to remove any measurement noise or baseline. Feature detection is applied to detect representations of measured ions from the processed raw signal. Alignment methods aim to cluster measurements across separate samples and normalization removes undesired systematic variation between different samples.
How to place an order:

*If your organization requires signing of a confidentiality agreement, please contact us by email




