K-means clustering is a method of vector quantization, resulting from signal processing, that is popular for cluster analysis in data mining. K-means clustering aims to divide n objects into k clusters in which each object belongs to the cluster with the nearest mean, serving as a prototype of the cluster. This results in a separation of the data space into Voronoi cells. Now, bioinformaticians at Creative Proteomics are proud to offer our customers Hierarchical Clustering Analysis service.
Demonstration of the standard algorithm for k-means clustering:
- K initial "means" are randomly generated within the data domain.
- K clusters are created by associating every observation with the nearest mean. The partitions here represent the Voronoi diagram generated by the means.
- The centroid of each of the k clusters becomes the new mean.
- Repeat steps 2 and 3 are until convergence has been reached.
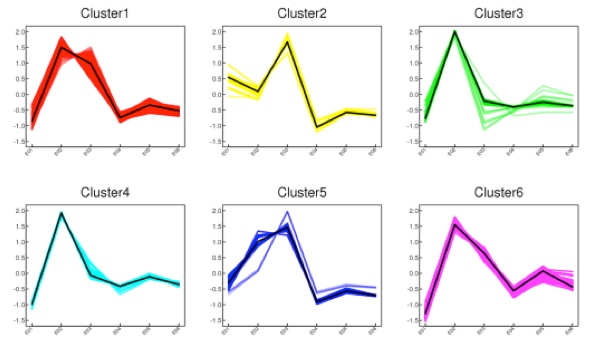
Advantages of k-means clustering
- Fast, robust and easier to use and understand.
- Relatively efficient: with a large number of variables, k-means may be computationally faster than hierarchical clustering method (if k is small).
- K-means may create tighter clusters than hierarchical clustering, particularly if the clusters are globular.
- Gives best result when data set are distinct or well separated from each other.
How to place an order:

*If your organization requires signing of a confidentiality agreement, please contact us by email
As one of the leading omics industry company in the world! Creative Proteomics now is opening to provide k-means clustering service for our customers. With rich experience in the field of bioinformatics, we are willing to provide our customer the most outstanding service! Contact us for all the detailed informations!




