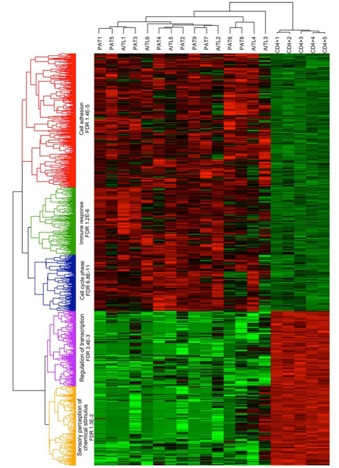
In statistics and data mining, hierarchical clustering (or hierarchical cluster analysis, HCA) is a method of cluster analysis which aims to build a hierarchy of clusters. This method produces a hierarchical decomposition of a given set of data objects. Now, bioinformaticians at Creative Proteomics are proud to tell you we are open to help you with Hierarchical Clustering Analysis Service!
We can classify hierarchical methods on the basis of how the hierarchical decomposition is formed. Strategies for hierarchical clustering generally can be divided into two types:
- Agglomerative: This approach is also known as the bottom-up approach: each instance starts in its own cluster, and pairs of clusters are merged as one move up the hierarchy. In this method, we start with each object forming a separate group. It continues to merging the groups or objects that are close to one another. It keeps on doing so until all of the objects are merged into one or until the condition of termination happens.
- Divisive: This approach is also known as the top-down approach: all observations start from one cluster, and splits are carried out recursively as one moves down the hierarchy. In this method, we start with all of the objects in the same cluster. In the process of iteration, a cluster is divided into smaller clusters. It is down until each cluster with only one object or the condition of termination happens.
Basic agglomerative hierarchical clustering algorithm
- Compute the proximity graph (if necessary)
- Merge the most similar or closest two clusters
- Update the proximity matrix to reflect the proximity between the new cluster and the original clusters
- Repeat steps 3 and 4 until all of the objects are merged into one cluster
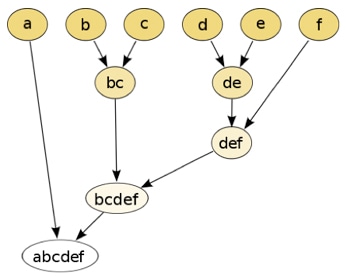
Simple divisive algorithm (divisive techniques are less common):
- Compute a minimal spanning tree of the proximity graph
- Create a new cluster by breaking the link corresponding to the smallest similarity with largest distance
- Repeat step 2 until only singleton clusters remain
Hierarchical clustering has the clear advantage that any valid measure of distance can be applied. In fact, the observations themselves are not required: all that is used is a matrix of distances.
How to place an order:

*If your organization requires signing of a confidentiality agreement, please contact us by email
As one of the leading omics industry company in the world! Creative Proteomics now is opening to provide hierarchical clustering service for our customers. With rich experience in the field of bioinformatics, we are willing to provide our customer the most outstanding service! Contact us for all the detailed informations!




