Start with the Membrane Question, Not the Analyte List
Workflow Type: Discovery vs. Targeted vs. Hybrid
Class-Level vs. Species-Level Interpretation
LC-MS/MS Behavior Across Phospholipid Classes
Sample Type Defines the Interpretation Ceiling
Pre-Analytical Variables and Sample Handling
Internal Standards and Normalization Logic
Phospholipid Annotation and Evidence Layers
Phosphoinositides: A Separate Decision Branch
Building a Multi-Evidence Chain
Project Readiness: Before and After Results
Frequently Asked Questions
Most pages about membrane lipids begin with the same foundation. They explain phospholipid head groups, acyl chains, leaflet asymmetry, membrane order, lipid rafts, and membrane fluidity. Those topics matter, but they do not answer the project question that appears later: what should be measured, in what sample type, with what LC-MS/MS logic, and how far can the result actually support a membrane claim?
The key project question is not what phospholipids are, but what level of assay evidence is needed for the membrane claim under review. A membrane phenotype and a phospholipidomics result are related, but they are not the same statement. A membrane phenotype may reflect curvature, protein crowding, cholesterol context, trafficking state, organelle mixing, local charge, or signaling microdomains. A phospholipidomics dataset reports compositional remodeling under a defined analytical workflow. It tells you which lipid signals changed. It does not, by itself, prove membrane mechanics, domain behavior, or protein recruitment.
This article helps research teams translate a membrane hypothesis into a workable phospholipidomics strategy. The focus is scientific logic, assay fit, and interpretation boundaries. For research use only.

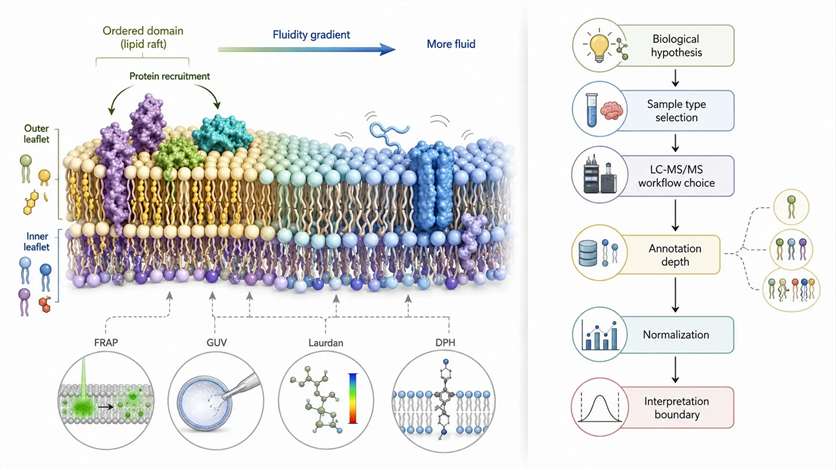
Figure 1. Boundary between membrane biophysics content and phospholipidomics decision content. What this figure helps decide: whether the reader needs a membrane-concept page or a workflow-selection page. What it does not prove: that any single membrane phenotype can be assigned to one lipid mechanism without assay-specific evidence.
Start with the Membrane Question, Not the Analyte List
A strong phospholipidomics project should begin with the membrane question, not with a list of analytes. The framing follows three steps:
- Phenomenon: something in the membrane-associated phenotype changes. Cells migrate differently. Vesicle formation shifts. A membrane protein redistributes. A stimulus alters trafficking or signaling behavior.
- Root cause: several explanations are still possible. The change may involve broad phospholipid class remodeling, acyl-chain remodeling within one class, low-abundance signaling lipids, altered organelle proportion, extracellular vesicle output, or sample composition rather than a direct shift in plasma membrane organization.
- Solution: define the smallest analytical question the assay must answer before choosing the workflow.
In practice, most membrane projects fall into four analytical question types:
- Class-level remodeling: Are PC, PE, PS, PI, PG, or PA moving in a coordinated way? This suits early-stage discovery and broad remodeling screens.
- Species-level remodeling within a class: Chain length, total unsaturation, and remodeling direction inside a class. Relevant when a mechanism depends on redistribution patterns.
- Phosphoinositide signaling pools: PI, PIP, PIP2, and PIP3 have central roles in membrane identity, trafficking, and receptor-linked signaling, but are not analytically equivalent to bulk phospholipid classes.
- Compartment-specific remodeling: Location matters as much as abundance. Plasma membrane, ER, mitochondria, and extracellular vesicles are distinct sample layers.
The practical mistake is to skip this sorting step and jump straight to "measure phospholipids." That often leads to mismatched assay design and over-interpretation later.
| Research Question | Preferred Assay | What It Can Support | What It Cannot Prove |
| Are major phospholipid classes shifting? | Broad discovery workflow | Direction of class-level remodeling | Direct proof of membrane mechanics |
| Are species within a class being remodeled? | Species-aware phospholipid workflow | Chain-length and unsaturation patterns | Full structural resolution for every signal |
| Are phosphoinositides driving signaling or membrane identity? | Dedicated targeted phosphoinositide workflow | Low-abundance signaling-pool changes | Whole-membrane composition on its own |
| Is remodeling compartment-specific? | Fraction-aware or compartment-aware workflow | Stronger compartment linkage | Pure leaflet assignment without special design |
Workflow Type: Discovery vs. Targeted vs. Hybrid
Once the membrane question is defined, the next major decision is workflow type.
- Discovery phospholipidomics makes sense when the biology is still open. You suspect membrane remodeling, but you do not yet know which phospholipid classes or species matter most. Discovery analysis is useful for comparing control and treated groups, identifying directional shifts, and generating candidates for follow-up work.
- Targeted phospholipidomics becomes more suitable when the project already has a narrower mechanistic focus. The biology may already point to a lipid class, a defined panel of molecular species, or a pathway-linked set of analytes. Targeted workflows improve consistency, signal focus, and interpretability.
- Hybrid workflow: Start with a broad workflow to locate the most informative lipid classes or species clusters. Then move to a narrower targeted design to validate the highest-value candidates.
The most useful rule: use discovery when you need to find the change; use targeted when you need to evaluate the change with a narrower follow-up design.
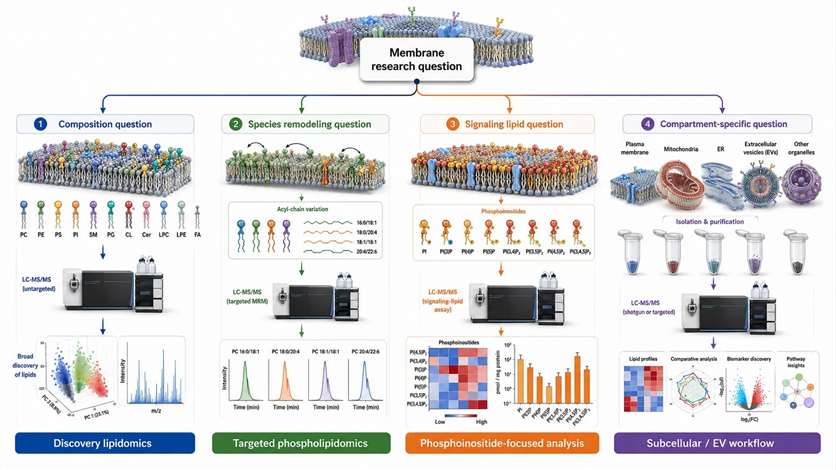
Figure 2. Decision tree linking membrane research questions to assay strategy. What this figure helps decide: whether the project should start with discovery, targeted phospholipidomics, phosphoinositide-focused analysis, or compartment-aware sampling. What it does not prove: that one workflow alone can resolve every layer of membrane biology.
| Workflow Type | Best Use | Main Strength | Main Caution |
| Discovery LC-MS/MS | Early-stage hypothesis generation | Broad remodeling view | Lower certainty for sparse or ambiguous signals |
| Targeted LC-MS/MS | Follow-up on defined candidates | More focused and stable measurement | May miss unexpected biology |
| Hybrid workflow | Open question with validation needs | Balances breadth and interpretability | Requires a disciplined phase transition |
| Validation panel | Mechanism support after discovery | Cleaner follow-up evidence | Not ideal as the first map when biology is unclear |
Three common design errors at this stage:
- Using untargeted data as mechanism proof — discovery results are often the right starting point, but not automatically the right stopping point.
- Starting with too narrow a panel too early — a panel can look clean and still miss the real remodeling pattern if the candidate list was locked before the biology was mapped.
- Failing to plan the transition from discovery to validation — the study is easier to interpret when the team defines in advance how discovery findings will be narrowed into a follow-up targeted design.
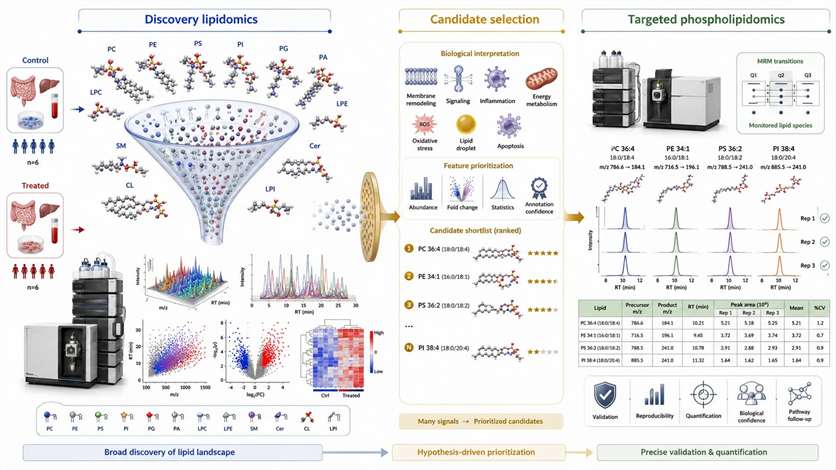
Figure 3. Two-stage phospholipidomics path from broad discovery to targeted validation. What this figure helps decide: when to stay broad and when to narrow into a follow-up design. What it does not prove: that discovery data alone is sufficient for every mechanism-level conclusion.
Class-Level vs. Species-Level Interpretation
A lipid name in a result table often looks more precise than the evidence behind it. Class-level data answers a family question — it tells you whether major phospholipid classes such as PC, PE, PS, PI, PG, or PA shifted as a group. Species-level data answers a finer question — it tells you whether specific molecular species within a class changed, where chain length, total carbon number, double-bond count, and ether or plasmalogen context begin to matter more.
Three critical boundaries apply to all phospholipid annotation:
- Naming: A reported signal such as PC 34:1 does not automatically mean one fully resolved structure. Class level, sum composition, fatty-acyl composition, and structurally resolved assignment are different annotation layers and should not be merged into a single confidence claim.
- Structural depth: A signal may support a class assignment or a sum composition, but that is not the same as resolving sn-position or double-bond position.
- Biological interpretation: A change in phospholipid species is not direct proof of membrane stiffness, membrane order, or domain organization. It is evidence of compositional remodeling that may be consistent with those membrane hypotheses.
| Result Type | What It Can Support | Where Caution Is Needed |
| Class-level result | Broad remodeling direction across phospholipid families | Cannot show which molecular species drive the shift |
| Species-level result | More specific remodeling patterns within a class | Does not automatically resolve all isomers or positions |
| Structural inference | Possible mechanism-linked context | Must match the actual evidence layer, not a preferred label |
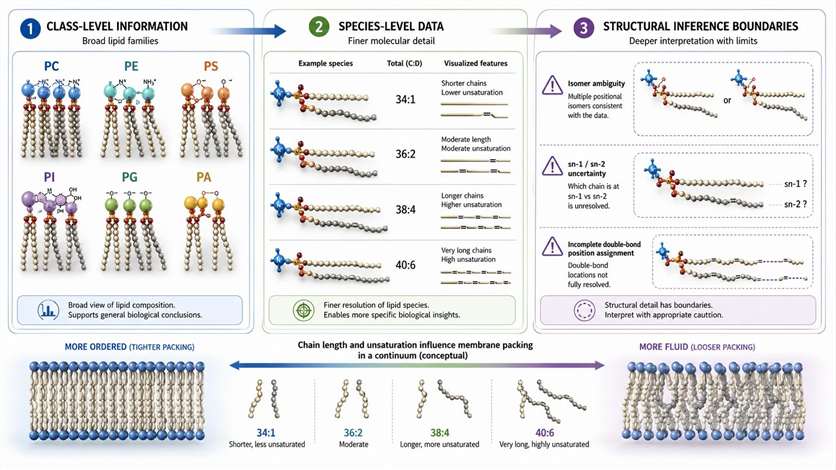
Figure 4. Evidence hierarchy for class-level and species-level phospholipid interpretation. What this figure helps decide: whether the project needs family-level profiling or deeper species-aware evidence. What it does not prove: that a lipid name in a result table automatically equals full structural resolution.
LC-MS/MS Behavior Across Phospholipid Classes
Phospholipids do not behave as one analytical family. Their head groups differ. Their ionization behavior differs. Their adduct patterns differ. Their fragmentation logic differs. Their susceptibility to in-source artifacts differs. Combined positive and negative ionization can broaden coverage, but even then, coverage and confidence remain class-dependent.
In practical terms:
- PC and LPC often show strong behavior in positive mode.
- PE, PI, PS, and PA often benefit from negative-mode logic or class-aware transition design.
- "Not detected" ≠ "not present": the class may be truly low, the method may not be optimized for that class, ion suppression may have reduced signal, or adduct competition may have complicated the spectrum.
This is why the more useful question is not "can you test phospholipids?" but whether the method supports the specific lipid classes, evidence level, and interpretation depth the project actually needs. A clearer understanding of Accurate Mass Determination is therefore part of study design. Mass Spectrometry Platform and Chromatography Technology can both support this layer of method planning.
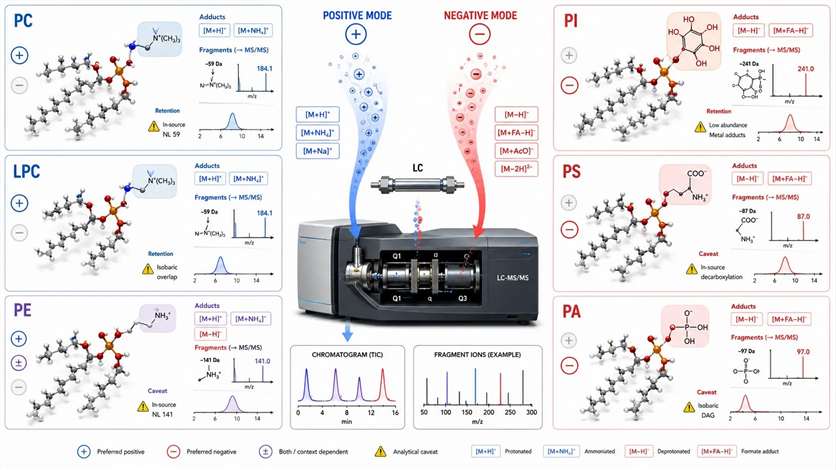
Figure 5. Ionization and fragmentation logic across phospholipid classes. What this figure helps decide: whether the project needs class-aware ionization and evidence planning. What it does not prove: that non-detection in one workflow means true absence in the sample.
Sample Type Defines the Interpretation Ceiling
Two datasets can be equally clean from an analytical standpoint and still support very different biological conclusions because the sample layer was different. The central rule: sample type does not only affect convenience — it defines the ceiling of interpretation. Membrane lipid composition varies across organelles and membrane systems, so changing the sample layer changes the biological meaning of the result.
| Sample Type | Best Question | Main Confounder | Recommended Control |
| Whole-cell extract | Is there broad remodeling? | Organelle mixing | Match biomass and treatment context carefully |
| Membrane-enriched fraction | Is membrane-associated remodeling present? | Fraction contamination or loss | Use enrichment controls and consistent processing |
| Subcellular fraction | Which compartment is changing? | Purity and cross-contamination | Pair with compartment markers or orthogonal evidence |
| EV or exosome sample | Is secreted membrane composition changing? | Isolation bias | Standardize preprocessing and QC |
| If Your Question Is… | Do Not Use Sample Type… | Because… | Use This Instead |
| Which organelle membrane is changing? | Whole-cell extract alone | It mixes all membrane systems into one signal | Subcellular fraction with purity controls |
| Is plasma membrane composition specifically shifting? | Whole-cell extract alone | It cannot isolate plasma membrane-enriched remodeling | Membrane-enriched fraction with orthogonal validation |
| Are leaflet-specific claims supportable? | Generic membrane extract | It does not resolve leaflet asymmetry by itself | A dedicated leaflet-aware design plus orthogonal evidence |
| Are vesicle membranes changing? | Bulk cell lysate | Vesicle-associated signals may be diluted or obscured | EV or exosome workflow |
| Is compartment-specific remodeling linked to protein context? | Lipid-only fraction without validation | Fraction quality and localization remain unclear | Pair lipidomics with protein-based fraction assessment |
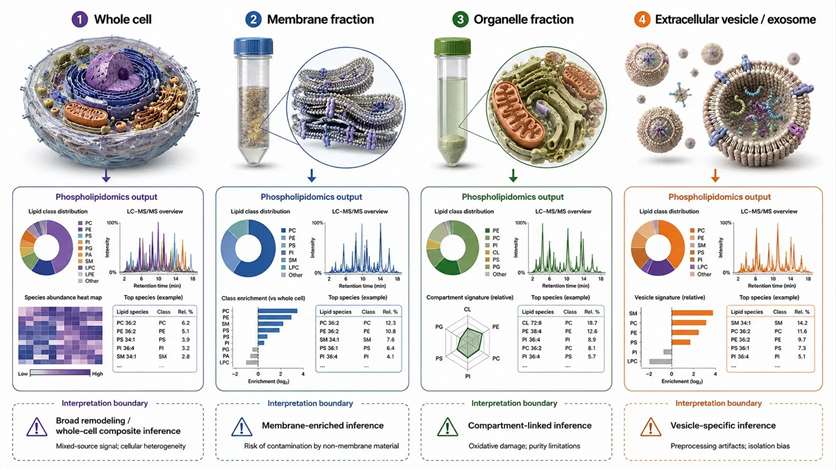
Figure 6. Interpretation boundaries across whole-cell, membrane-enriched, subcellular, and extracellular vesicle samples. What this figure helps decide: which sample layer matches the biological question under review. What it does not prove: that enrichment alone guarantees compartment purity or leaflet-specific interpretation.
Adjacent workflows: Subcellular Proteomics can strengthen confidence in the sample layer. Exosome Lipidomics may fit better for vesicle-centered studies. Membrane Protein Identification can help connect lipid remodeling to membrane-associated protein changes.
Pre-Analytical Variables and Sample Handling
For many membrane projects, the biggest distortion does not begin in the mass spectrometer. It begins before extraction. Phospholipid readouts are sensitive to how samples are harvested, quenched, extracted, stored, thawed, and normalized. A common example is an apparently elevated LPC or LPE signal — that pattern may reflect real biology, or it may appear when phospholipids are hydrolyzed during handling, when the processing window is too long, or when freeze-thaw stress introduces bias.
The most useful rule: if a phospholipid pattern could have been created by handling, do not assign it to biology before checking the handling logic.
| Pre-Analytical Variable | Affected Signal Pattern | Main Risk | Control Strategy |
| Quenching speed | Broad remodeling drift | Ongoing metabolism after collection | Standardize fast, cold handling |
| Extraction solvent and phase behavior | Class-dependent recovery changes | Biased extraction efficiency | Use one validated extraction scheme across groups |
| Freeze-thaw frequency | Lysolipid and oxidation-sensitive shifts | Degradation or partial hydrolysis | Aliquot early and record thaw cycles |
| Residual water, salt, or protein contamination | Signal suppression or instability | Matrix effect | Keep cleanup consistent across samples |
| Sample mass or biomass inconsistency | Apparent abundance differences | False biological contrast | Match input and document normalization basis |
| Harvesting method | Stress-linked remodeling artifacts | Handling-induced lipid change | Keep collection logic identical across groups |
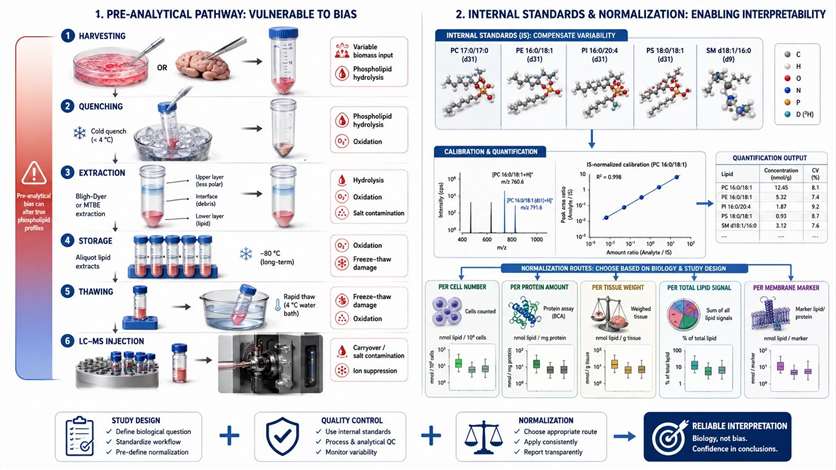
Figure 7. Pre-analytical risk map for phospholipid studies. What this figure helps decide: which handling steps are most likely to distort the phospholipid readout before LC-MS/MS begins. What it does not prove: that a single abnormal lipid pattern is biological rather than pre-analytical in origin.
Internal Standards and Normalization Logic
Many researchers assume that quantification becomes reliable once the instrument is sensitive enough. In practice, interpretability depends just as much on internal standards and normalization logic. Internal standards help monitor extraction efficiency, compensate for part of the ionization drift, and support class-aware semi-quantitative interpretation — but they cannot rescue inconsistent sampling, fully remove all matrix effects, or turn relative quantification into absolute quantification unless the method and calibration strategy are built for that purpose.
The right normalization question is not "which normalization is standard?" but "which normalization matches the biology without masking it?"
| Normalization Method | Best Use Case | Failure Mode | Reporting Note |
| Per cell number | Controlled cell systems with stable cell size | Misleading when treatment changes cell size or membrane area | Report counting method clearly |
| Per protein amount | Samples with stable protein context | Biased when treatment shifts protein mass | State whether protein change is part of biology |
| Per tissue weight or biomass | Tissue or bulk-input studies | Can miss composition shifts tied to cellularity | Define input basis precisely |
| Per total lipid signal | Useful for profile comparison in some datasets | Can mask global lipid-mass changes | Use with caution when total lipid pool shifts |
| Per membrane-fraction marker | Compartment-focused studies | Depends on fraction quality | Pair with fraction-quality evidence |
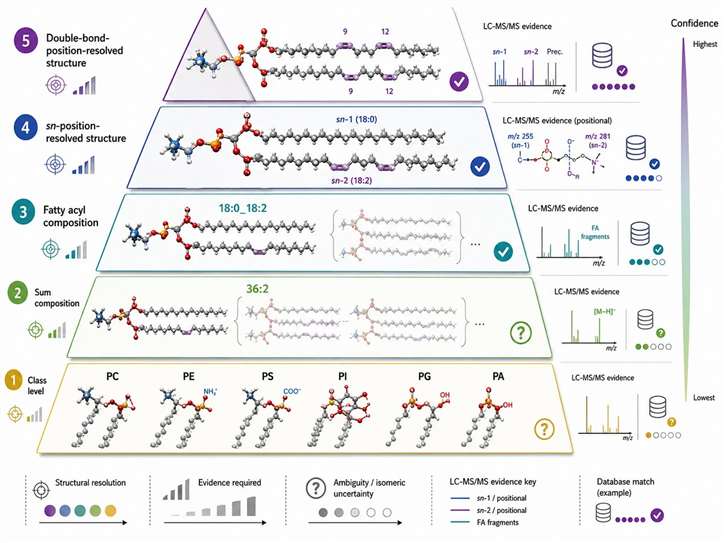
Figure 8. Internal standards and normalization decision matrix. What this figure helps decide: which quantification strategy best matches the sample model and reporting goal. What it does not prove: that stronger instrument sensitivity alone guarantees interpretable quantification.
Phospholipid Annotation and Evidence Layers
A lipid name in a result table often looks more precise than the evidence behind it. Different name formats represent different resolution levels:
- Class name only (e.g., PC): class evidence — a phosphatidylcholine-class signal is present
- Sum composition (e.g., PC 34:1): total carbon and double-bond count are assigned
- Fatty-acyl composition (e.g., PC 16:0/18:1): likely acyl composition is supported, but sn-position is not automatically known
- More resolved structural form: specialized structural evidence required
| Reported Name | Evidence Required | Safe Interpretation | Unsafe Interpretation |
| PC | Class evidence | A phosphatidylcholine-class signal is present | Specific molecular structure is known |
| PC 34:1 | Sum composition evidence | Total carbon and double-bond count are assigned | Exact acyl pairing or position is proven |
| PC 16:0/18:1 | Fatty-acyl composition support | Likely acyl composition is supported | sn-position is automatically known |
| More resolved structural form | Specialized structural evidence | Higher structural confidence with proper method | Universal routine annotation assumption |
A cautious annotation is not a weakness — it is a sign that the evidence boundary is being respected. When a project includes ambiguous or unexpected lipid features, Unknown Metabolites Identification and Accurate Mass Determination can help define what level of structural claim is actually justified.
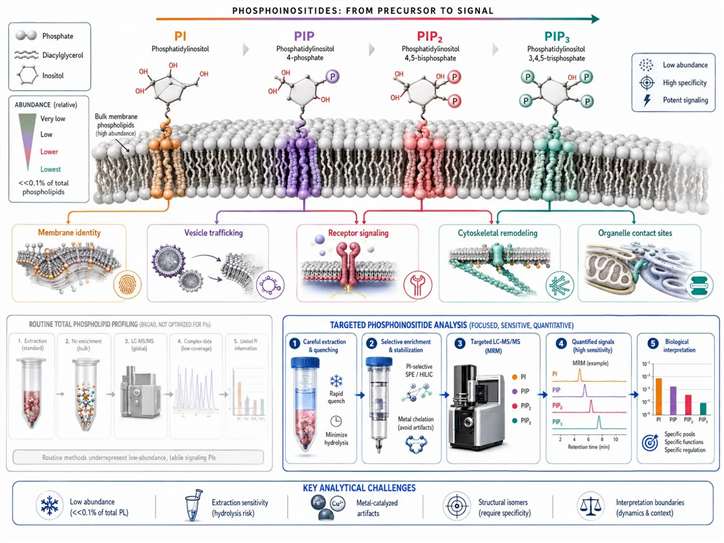
Figure 9. Phospholipid annotation pyramid. What this figure helps decide: what level of structural interpretation is supported by the reported lipid name. What it does not prove: that every reported species has been fully structurally resolved.
Phosphoinositides: A Separate Decision Branch
Phosphoinositides should not be treated as a small extra feature inside a general phospholipid workflow. In many membrane projects, they are a separate decision branch. PI, PIP, PIP2, and PIP3 function as low-abundance signaling lipids that shape membrane identity, vesicle trafficking, receptor signaling, cytoskeletal remodeling, and subcellular organization. These pools are dynamic, localized, and often mechanistically important even when their absolute abundance is low.
The analytical reason is just as important: a change in total PI does not answer the same question as a change in PIP2 or PIP3. The practical rule: separate the phosphoinositide question from the bulk phospholipid question and design the assay accordingly.
| Lipid Pool | Biological Question | Analytical Concern | Recommended Workflow |
| PI | Is the phosphatidylinositol class shifting? | May not resolve signaling pools | Broad or targeted phospholipid profiling |
| PIP | Is early phosphoinositide remodeling present? | Low abundance and context sensitivity | Dedicated targeted workflow |
| PIP2 | Is receptor-linked or membrane-identity signaling changing? | Requires careful specificity | Targeted phosphoinositide analysis |
| PIP3 | Is acute signaling activation implicated? | Very low abundance and dynamic turnover | Phosphoinositide-focused design |
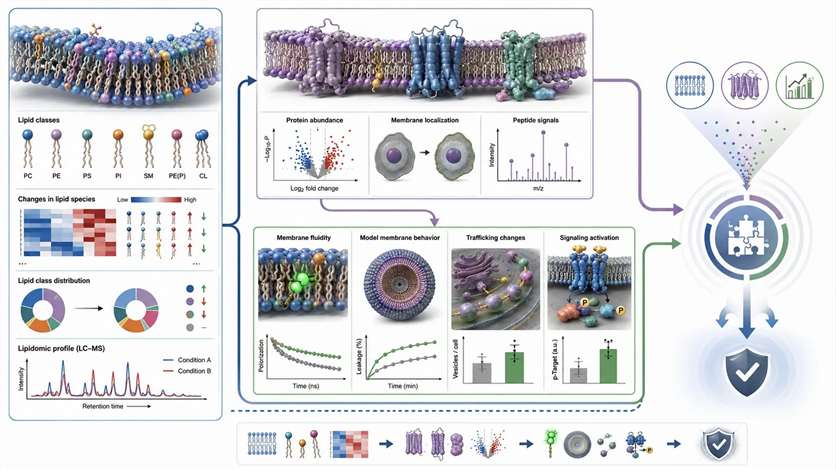
Figure 10. From PI to PIP3: analytical and biological stratification of phosphoinositides. What this figure helps decide: when the project should move from general phospholipid profiling to a phosphoinositide-focused workflow. What it does not prove: that total PI behavior can substitute for direct evidence on low-abundance signaling pools.
Building a Multi-Evidence Chain
Phospholipidomics becomes much more informative when it is placed inside a broader evidence chain. Lipidomics tells you which lipid classes or molecular species changed. It does not automatically tell you whether membrane protein recruitment changed, whether membrane order shifted, or whether trafficking behavior changed for the reason you think it did. The strongest membrane studies combine phospholipidomics with orthogonal evidence.
| Lipidomics Evidence | Orthogonal Readout | Interpretation Strength | |
| Membrane protein relocalization | Specific lipid classes or species shifted | Membrane proteomics or localization assay | Moderate to strong when aligned |
| Vesicle-trafficking phenotype | Phosphoinositide-linked or membrane-class remodeling | Functional trafficking assay | Stronger than either layer alone |
| Broad membrane-state change | Global class remodeling | FRAP, Laurdan, GUV, or related readout | Better support for mechanism consistency |
| Pathway-linked remodeling | Coherent lipid shifts across classes | Pathway-level bioinformatics | Stronger biological framing, not direct proof |
Adjacent services: Membrane Protein Identification can add protein context specificity. Integrated Proteomics and Lipidomics Analysis can help connect lipid remodeling to protein-level change. Bioinformatics for Metabolomics can help organize signals without overstating what they prove.
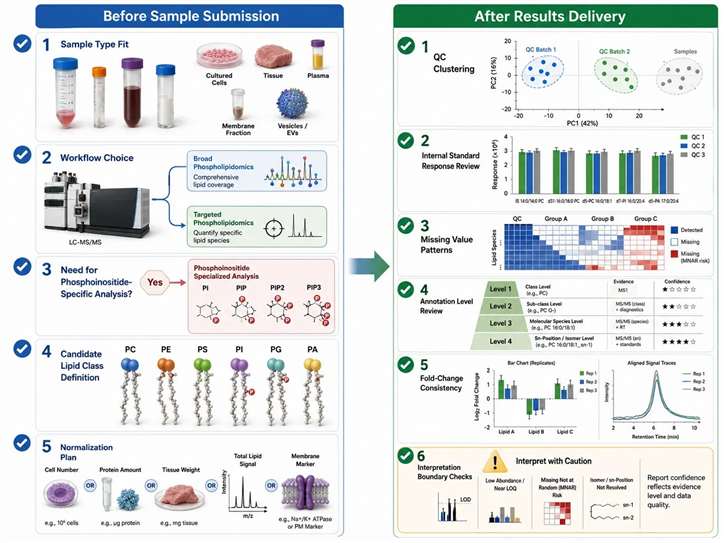
Figure 11. Multi-evidence chain linking phospholipidomics, membrane proteomics, and functional membrane readouts. What this figure helps decide: how to strengthen mechanism-level interpretation with orthogonal evidence. What it does not prove: that any single omics layer alone can fully resolve membrane mechanism.
Project Readiness: Before and After Results
The best phospholipidomics projects are often distinguished by the questions asked before samples are sent and before conclusions are written.
Before submission — fit questions:
- Does the sample type match the membrane question?
- Is the project exploratory enough to require discovery, or focused enough for targeted analysis?
- Does the biology point to phosphoinositides strongly enough to justify a dedicated workflow?
- Is the intended normalization logic already compatible with the sample model?
After results — data behavior questions:
- Are QC samples behaving consistently?
- Are internal-standard responses stable enough to support interpretation?
- Are missing values concentrated in particular lipid classes?
- Is the annotation level clearly stated?
- Does fold change align with class-level directionality, or is the conclusion being built on isolated features with weak contextual support?
| Buyer Question | Technical Question Behind It | Data Requirement |
| I need to see what changed first | Is the biology still open? | Broad class and feature coverage |
| I need to validate a candidate phospholipid set | Is there already a shortlist? | Focused species-level consistency |
| I need to interpret membrane signaling sites | Are phosphoinositides central to the model? | Dedicated low-abundance signaling-lipid coverage |
| I need stronger compartment linkage | Does location define the mechanism? | Fraction-aware sample design and validation |
| I need stronger protein-context evidence | Is membrane protein change part of the mechanism? | Cross-evidence integration |
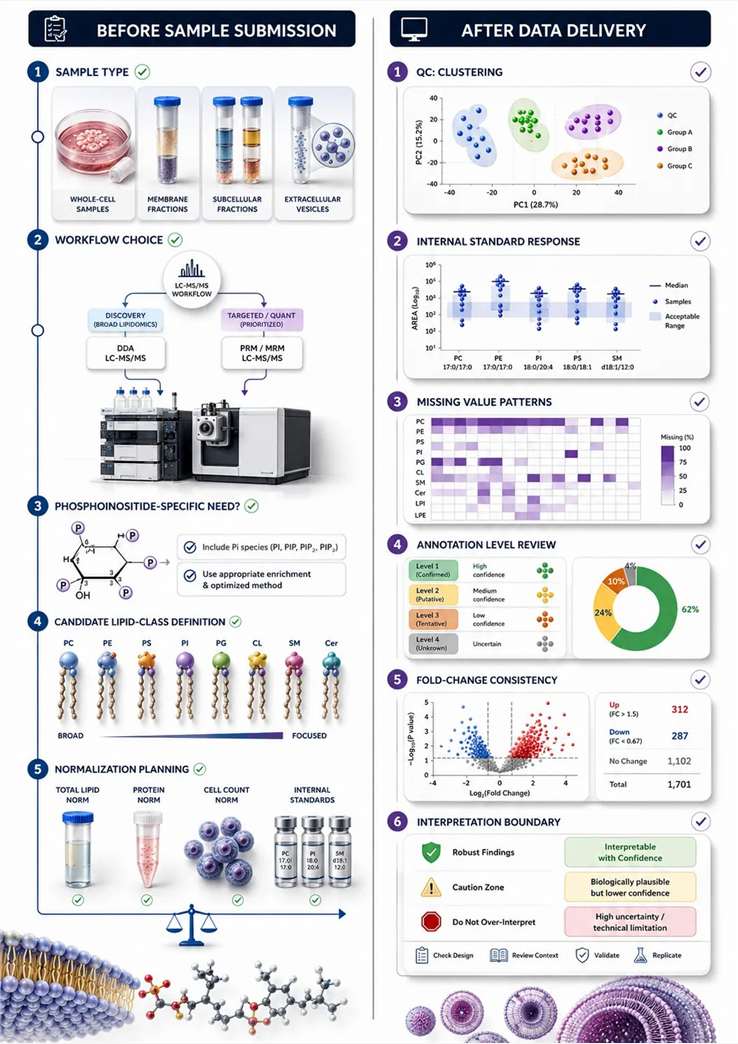
Figure 12. Buyer-side phospholipidomics project checklist. What this figure helps decide: whether the project is ready for discovery, targeted follow-up, phosphoinositide-specific work, or compartment-aware design. What it does not prove: that a good purchasing decision alone guarantees a strong biological conclusion.
Frequently Asked Questions
It can be enough for early discovery and broad remodeling screens. It is usually not enough when the main question depends on low-abundance signaling pools, narrow candidate validation, or deeper structural interpretation.
Targeted analysis is most useful when you already have a shortlist of candidate lipid classes or molecular species, or when you need a cleaner follow-up design after discovery.
Sometimes, but not automatically. Routine phospholipid workflows do not always resolve sn-position, double-bond position, or every isomeric alternative. Reported annotation should match the evidence level.
Not on its own. Phospholipidomics can show compositional remodeling that may be consistent with a membrane-fluidity hypothesis, but direct support usually requires orthogonal membrane-state readouts.
The normalization basis should match the biological model. Per-cell, per-protein, per-biomass, total-lipid, and compartment-linked normalization each have useful contexts and clear failure modes.
That depends on the question. Whole-cell extracts are useful for discovery. Membrane-enriched fractions are closer to membrane questions. Subcellular fractions are better for compartment-specific hypotheses. EV or exosome samples are better for vesicle-centered questions.
It can suggest system-level remodeling, but it cannot directly isolate plasma membrane-specific change without a more specific sample design.
When the hypothesis centers on membrane identity, vesicle trafficking, receptor signaling, cytoskeletal remodeling, or other localized signaling events, phosphoinositides usually need their own workflow.
For research use only. Not for diagnostic or clinical applications.