Antibodies (Ab), integral elements of the immunoglobulin (Ig) secreted by immune cells, serve as a crucial part of the body's adaptive immune system. These immune molecules possess an inherent capability to specifically bind to antigens and stimulate immune responses in the organism. The multidimensionality of an antibody's structure makes it a biological cornerstone for adaptive immunity and extensive antigen recognition.
With the rapid development of biotechnology and advancements in information technology, a significant amount of immunologically relevant biological data has been accumulated. Consequently, the emergence of immunoinformatics was inevitable; its purpose being to leverage this massive data repository for storage, management, retrieval, research, and application, thereby unraveling patterns pertinent to immunology.
Antibody informatics, a critical constituent of immunoinformatics, involves the study of concepts related to immunoglobulins or antibodies, along with a variety of databases and tools utilized for the storage and analysis of immunoglobulin or antibody data and their properties. These antibody databases primarily handle the collection and management of information concerning the genes, protein sequences, and structures of immunoglobulins or antibodies. This allows for a correlation between the structure and function of antibodies, driven by antibodies sequence and structural information. Since the establishment of the inaugural antibody database, Kabat, in 1970, several databases related to the field of immunogenetics, especially those concerning antibodies, have successively emerged. Amongst them, large-scale commonly used databases include the international immunogenetics information system IMGT that caters to immunoinformatics, as well as the antibody online analysis system, abYsis.
Select Service
Commonly Used Database
1. Kabat Database
The Kabat database, established in 1970 by renowned immunologist Elvin A Kabat and his research team, was pioneered to determine antigen-binding sites on the light and heavy chains of antibodies. As the first global immunology database, the Kabat database has long been revered by researchers in relevant research fields. The Kabat database was made public in 1976 in Kabat's publication 'Sequences of Proteins of Immunological Interest' and underwent five substantial expansions and revisions until 1991. Along with the influx of nucleic acid and protein sequence information of immunoglobulins, T-cell receptors, MHC-I and MHC-II molecules, and other immune-related proteins into the Kabat database, it officially went online in 1991.
With the addition of new sequences, the Kabat database continually expanded and enriched its information analysis toolkit. By July 2000, the database comprised 19,382 sequences of diverse categories from 70 different species, of which 7,989 sequences were thoroughly annotated. The tools offered by the Kabat database include advanced database sequence search (seqhunt II), sequence alignment for antibodies and other immune-related proteins (Align-A-Sequence), subgrouping, current counts, family analysis (Find Your Families), and variability analysis.
2. IMGT
IMGT (ImMunoGeneTics) was initiated by Marie-Paule Lefranc (University of Montpellier II, CNRS) in 1989 and has since established itself as a globally recognised system for immunogenetics and related protein information. It now serves as a portal for worldwide immunogenetic data. IMGT provides data on genomics, proteomics, genetics, and two-dimensional and three-dimensional structural information of proteins related to immunology. The preciseness and consistency of the data are ensured by IMGT-ONTOLOGY, which stands as the sole ontology in the field of immunogenetics and immunoinformatics. Not only is IMGT-ONTOLOGY the standard for IMGT data management, it also forms the cornerstone for the construction of resource repositories.
Based on the axioms propounded in IMGT-ONTOLOGY, immunoglobulin-related data resources within IMGT are categorized into four types and are maintained and monitored across seven sub-databases. These encompass sequence databases (IMGT/LIGM-DB, IMGT/PRIMER-DB, IMGT/CLL-DB), gene databases (IMGT/GENE-DB), structural databases (IMGT-3Dstructure-DB, IMGT/2Dstructure-DB), and a monoclonal antibody database (IMGT/mAb-DB). A logical correlation exists between these sub-databases and their respective software tools.
IMGT/LIGM-DB is a detailed annotated database of human and other vertebrate Immunoglobulin (Ig) and T cell receptor (TCR) sequences, containing almost 180,000 sequences from 351 species. The IMGT/PRIMER-DB provides standardized data of Ig and TCR primers from 11 species, totaling in 1864 entries, which proves highly beneficial for research on the protein expression of Ig and TCR under both normal and pathological states, as well as construction of antibody libraries. IMGT/CLL-DB primarily collects Ig sequences from patients with Chronic Lymphocytic Leukemia and requires registration for use. IMGT/GENE-DB is a genomic database offering sequences, classifications, international nomenclature, chromosome positioning information, and more for human, mouse, and other vertebrate Ig and TCR genes.
IMGT/2Dstructure-DB and IMGT/3Dstructure-DB are structure databases, with the former being part of the latter, managing and providing sequence information from the INN/WHO and Kabat databases to the 3Dstructure-DB in a unique IMGT encoding manner. IMGT/3Dstructure-DB manages and shares the three-dimensional structure of Ig, TCR, MHC, and RPI as well as related interaction information from the PDB database. IMGT/mAb-DB is a monoclonal antibody database, collecting monoclonal antibodies and fusion proteins for immunization besides those used for diagnosis or treatment.
Sanitizing over 15,000 resource pages, IMGT portal site provides 17 supportive analysis tools that dovetail with the databases. These tools are divisible into categories according to their functions: sequence analysis, gene analysis, and structural display/analysis. With regards to antibody analysis, sequence analysis tools include IMGT/V-QUEST, IMGT/HighVQUEST, IMGT/StatClonotype, etc.; gene analysis tools include IMGT/LocusView, IMGT/GeneView, etc.; and structural display and analytical tools include IMGT/DomainDisplay, IMGT/DomainGapAlign, among others.
Currently, IMGT is extensively utilized in antibody design, analysis, optimization, transformation, and other research and development related to biotechnology. All resources are accessible free of charge through their homepage at www.imgt.org.
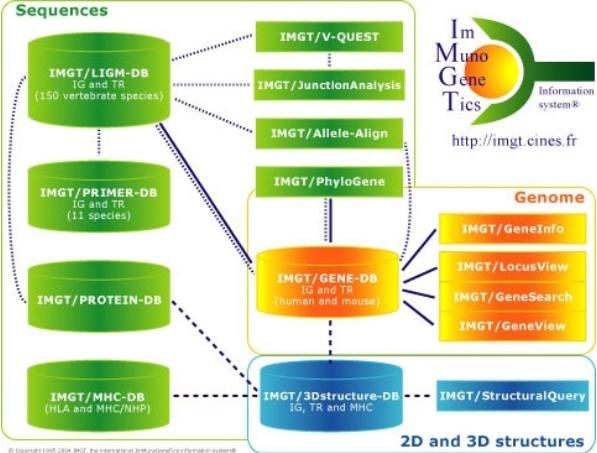 IMGT, the international ImMunoGeneTics (Marie-Paule Lefranc 2015)
IMGT, the international ImMunoGeneTics (Marie-Paule Lefranc 2015)3. abYsis
AbYsis, an online antibody research system developed by Andrew C.R. Martin's research group, encapsulates both antibody sequence and structure information. It integrates sequence information from the EMBL-ENA and Kabat databases, along with structural information from the PDB database, covering 15 species including humans, mice, rats, crab-eating macaques, and alpacas. Based on a PostgreSQL relational database, abYsis supports four types of functionalities: keyword search, structure-based search, sequence-based search, and distribution search based on amino acid frequency or regional frequency (such as CDR or FR regions).
abYsis processes antibody data from EMBL, PDB, and FASTA coded formats. Utilizing gene modeling tools, it links DNA and protein sequences, and provides a Germline view to facilitate users in researching sequences at the genomic level. The system annotates antibody sequences using the classic position coding methods of Kabat, and Chothia, capturing key information such as CDR region division and post-translation modification sites. Furthermore, it makes canonical class predictions for the antibody CDR region based on published methods.
Within the umbrella of antibody research, the AbYsis database (http://abysis.org/) provides an extensive range of resource and analytic tools for scientists. One of its salient features is its capacity to present data on the positional and species-specific distributions of amino acid residues within antibody sequences. Furthermore, AbYsis excels in identifying infrequently occurring residues at specific positions, lending significant aid to researchers attempting to construct viable amino acid mutation matrices—especially when assessing antibodies derived from varied species.
In addition to the above, AbYsis is equipped with an expansive toolkit designed to manage, analyze, and forecast antibody data. Key amongst these tools are: KabatMan for Kabat coded sequence data searches, the Abnum for antibody sequence coding, G-score and H-score assessments to measure the degree of humanization, the PAPS for predicting light and heavy chain angles, Chothiacanonicals to predict Chothia canonical classes, and SeqTest to prognosticate the occurrence of rare residues.
In summation, the AbYsis platform serves as an invaluable resource for antibody investigation, offering a diverse set of tools suitable for all levels of antibody examination, facilitating enhanced research and discovery within this field.
4. ARP
The Antibody Resource Page (ARP), available at https://www.antibody society.org/resources/, is widely recognized as a pivotal repository for internet resources in the field of antibody studies. Not only does the ARP comprehensively categorize and detail the offerings of over 180 global antibody suppliers, but it also provides various resources that are closely tied to antibody research. These include guidelines for biological experiments such as antibody preparation and detection, as well as antibody-related databases and analytical tools. Additionally, the site amasses a vast collection of antibody-related images and thematic introductions, education and publishing resources related to antibody research. This fully caters to the needs of a variety of suppliers, researchers, and users engaged in antibody production, sales, procurement, usage, and research and development.
Other Database
Within the field of antibody research, there are several distinctive, specialized databases in addition to the commonly used resources mentioned. For example, Citeab (https://www.citeab.com/), the largest global antibody search engine, is known for its search results ranked by citation counts. Antibody Registry (https://antibodyregistry.org/) aims to provide unique identifiers for each antibody from multiple sources to facilitate search and citation. The Antibody Validation Database (http://compbio.med.harvard.edu/antibodies) is unique in that it collects laboratory results of commercial antibodies to validate their quality and efficacy. The Structural Antibody Database (SACS) uses self-curating programs to collate data about antibody crystal structures derived from structural database PDB. Meanwhile, the Structural Antibodies Database (SAbDab, http://opig.stats.ox.ac.uk/webapps/newsabdab/sabdab/) is known for its capacity to automatically collect, synthesize, and annotate structural information about known antibodies, including experimental data, gene and antigen information and antigen-antibody affinity. These databases, combined with the common antibody resource databases detailed above, collectively constitute a crucial set of references for antibody research, modification, and production.
In Conclusion
With the deepening understanding of antibody research, various antibody resource databases have emerged, catering to the needs of antibody development, production, and usage. Comprehensive databases like IMGT and abYsis offer services for the search, retrieval, and analysis of antibody sequence, structure, and functional epitope information, supporting the design, research, and validation of antibodies.
Researcher should take note of the differences in antibody sequence coding methods of different databases when using resources like IMGT and abYsis. IMGT, for example, uses a unique coding methodology, whereas abYsis provides options for Kabat, Chothia and Chothia coding systems. Different coding methodologies may lead to varying definitions of the starting and ending positions of CDR and FR regions in the same antibody variable region.
Forty years of development in antibody resource databases has seen them evolve amid the surge in antibody-related research and data availability. These databases are becoming larger in scale and more refined in function. As the number of antigen structures and antigen-antibody complex structures increase, databases revolving around patterns of mutual recognition, antibody structure analysis, and epitope databases will further develop as the foundation for antibody optimization. The role and significance of antibody databases in research, development, production, and sales of antibodies will become increasingly critical.
Related Services