CORE SERVICE
Array-Based Protein Profiling — High-Throughput, Low-Input, Multiplexed Analysis
Mass spectrometry-based proteomics excels at unbiased discovery across the full proteome, but array-based protein profiling occupies a complementary and in many applications superior niche: when your question is about a defined set of proteins, antigens, or analytes, and you need to screen them across many samples simultaneously with minimal sample consumption, protein and antibody arrays deliver throughput and sensitivity that LC-MS/MS workflows cannot match.
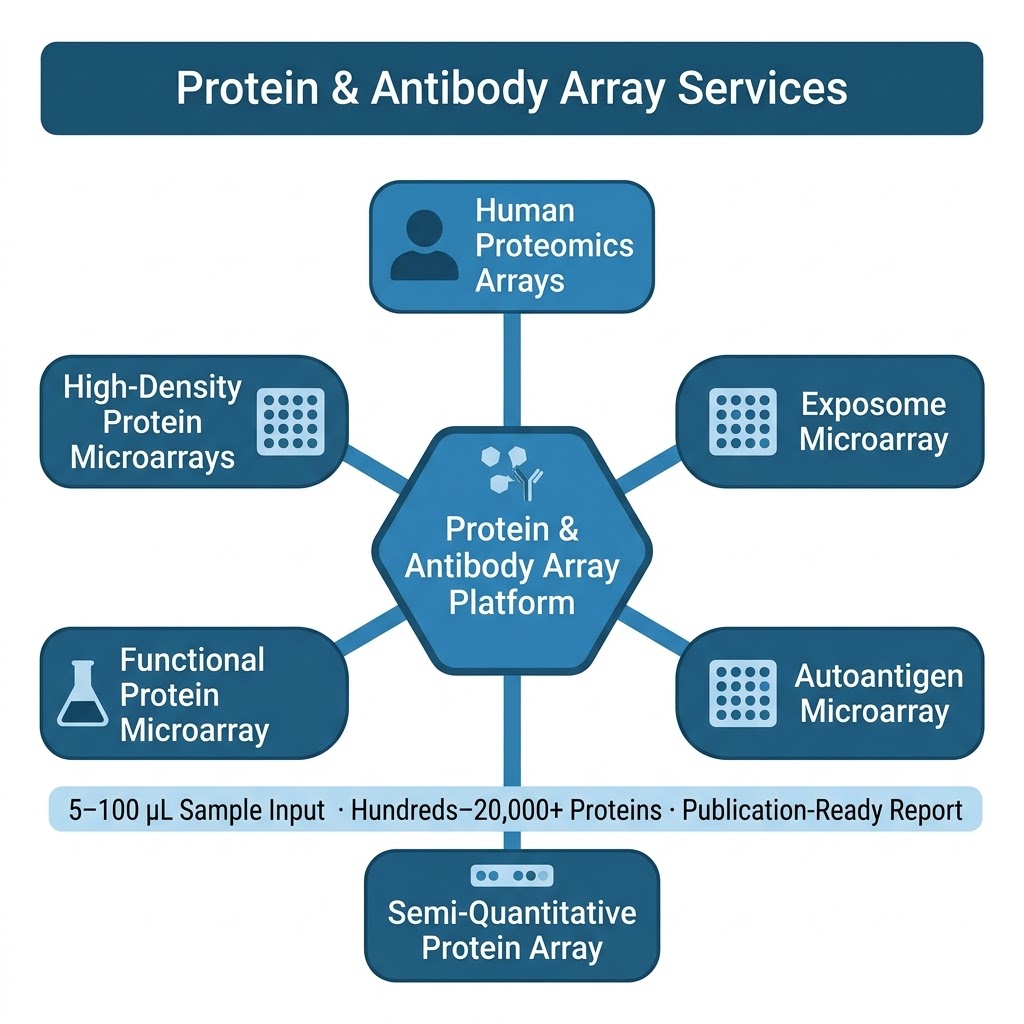
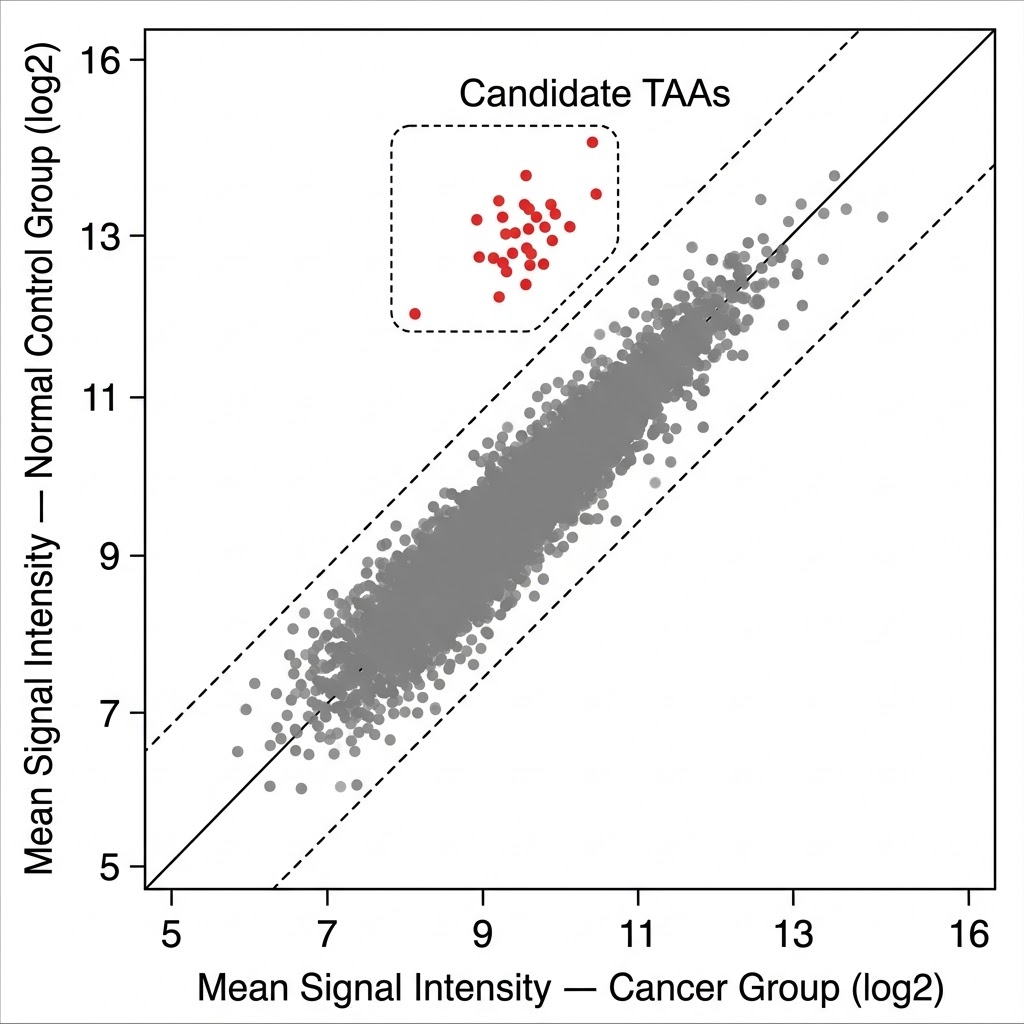
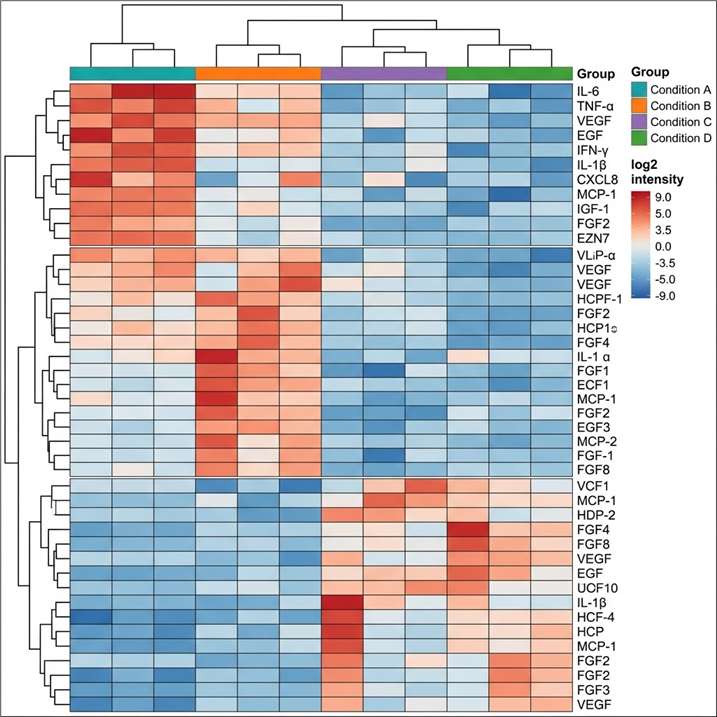
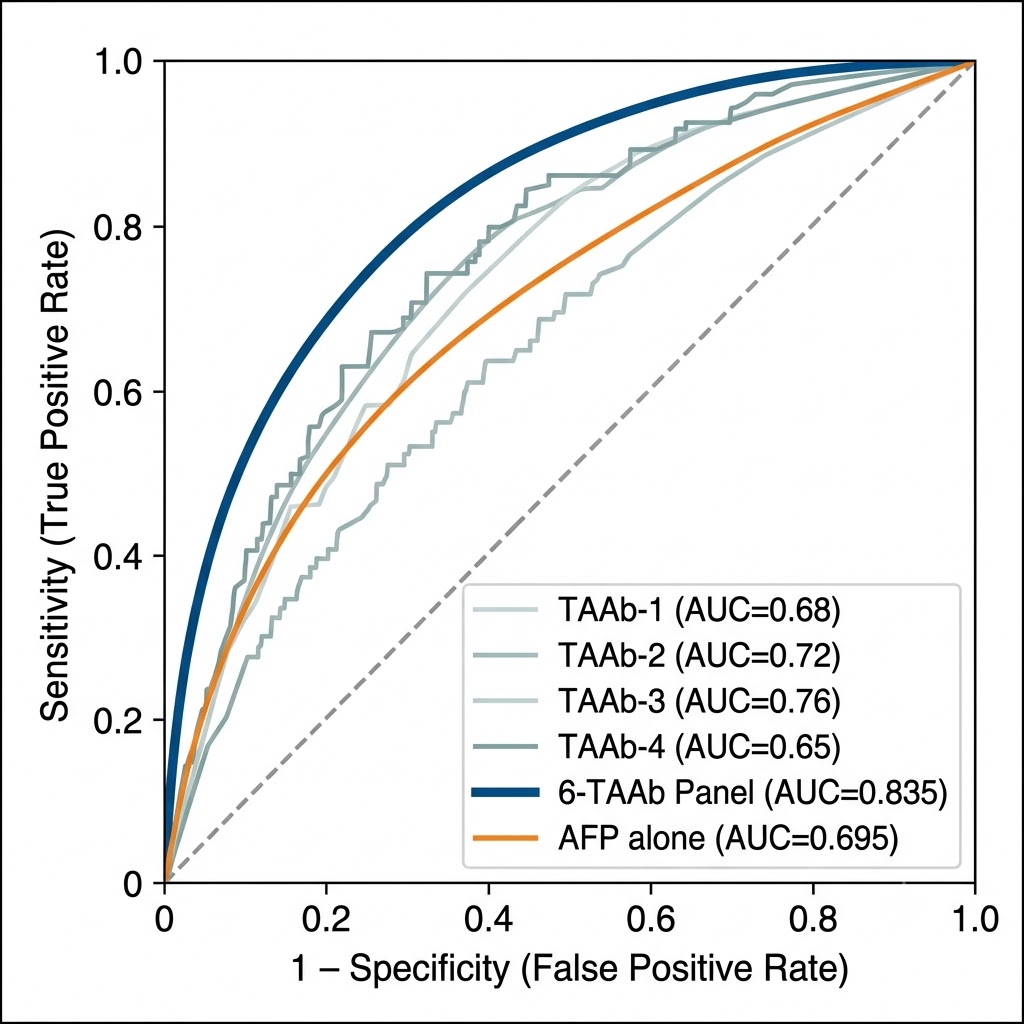
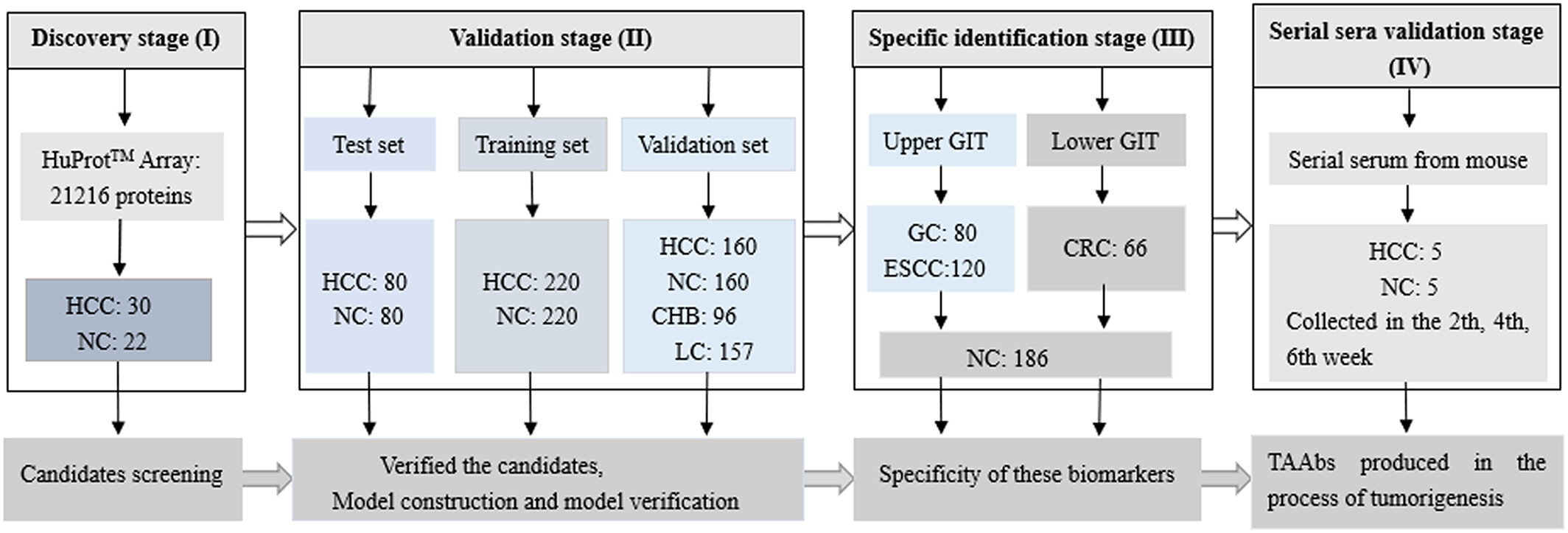
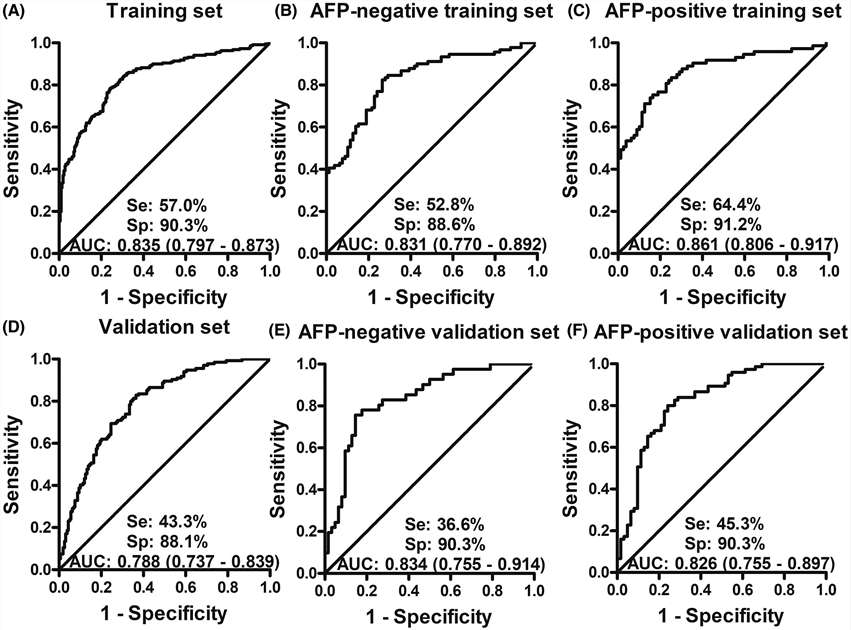
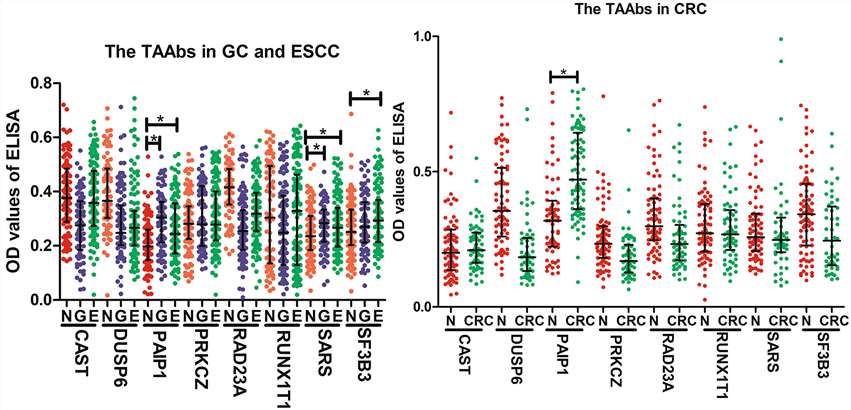
Our Protein & Antibody Array Services cover six distinct array formats, each designed for a specific class of biological question — from proteome-wide autoantibody discovery using arrays bearing over 20,000 full-length human proteins, to focused semi-quantitative cytokine and growth factor profiling from 10–50 μL plasma, to functional screening of protein-protein, protein-lipid, and protein-small molecule interactions on arrays of purified recombinant proteins. All formats are available as fully managed CRO services: you ship samples, we handle array processing, imaging, data extraction, normalization, and statistical analysis, and deliver a publication-ready report.
- Proteome-scale or targeted: Array formats span from >20,000-protein full human proteome coverage (HuProt-format arrays) to custom 40–1,000 analyte panels, giving you the right resolution for discovery or validation phases.
- Minimal sample input: Most array formats require only 10–100 μL serum, plasma, or cell lysate per sample — enabling rare sample types, longitudinal cohorts, and pediatric or biopsy-scale biospecimens that cannot support LC-MS/MS workflows.
- High sample throughput: Array formats support screening of 10–500+ samples per project. Cohort-scale autoantibody screening, cross-sectional biomarker studies, and multi-group exposure profiling are all feasible within a single project engagement.