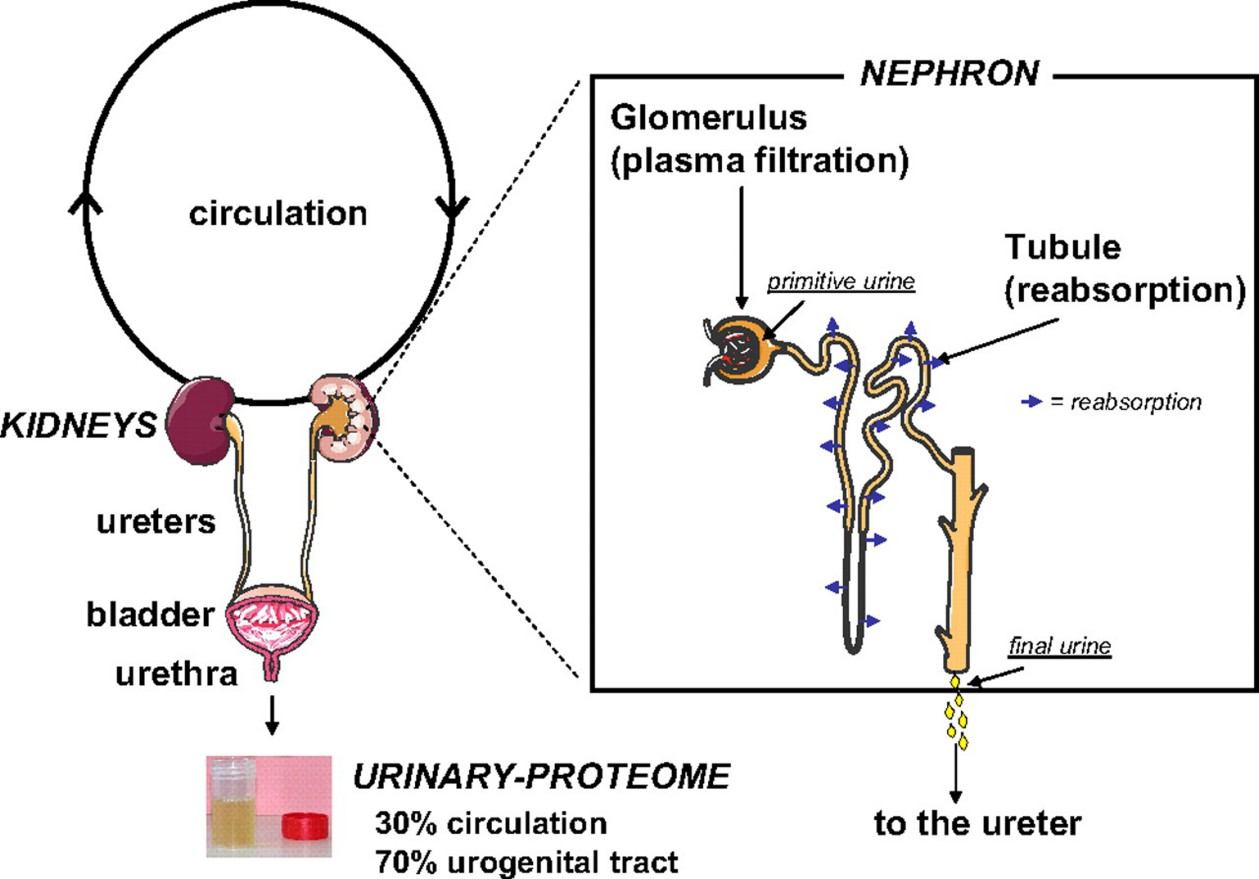
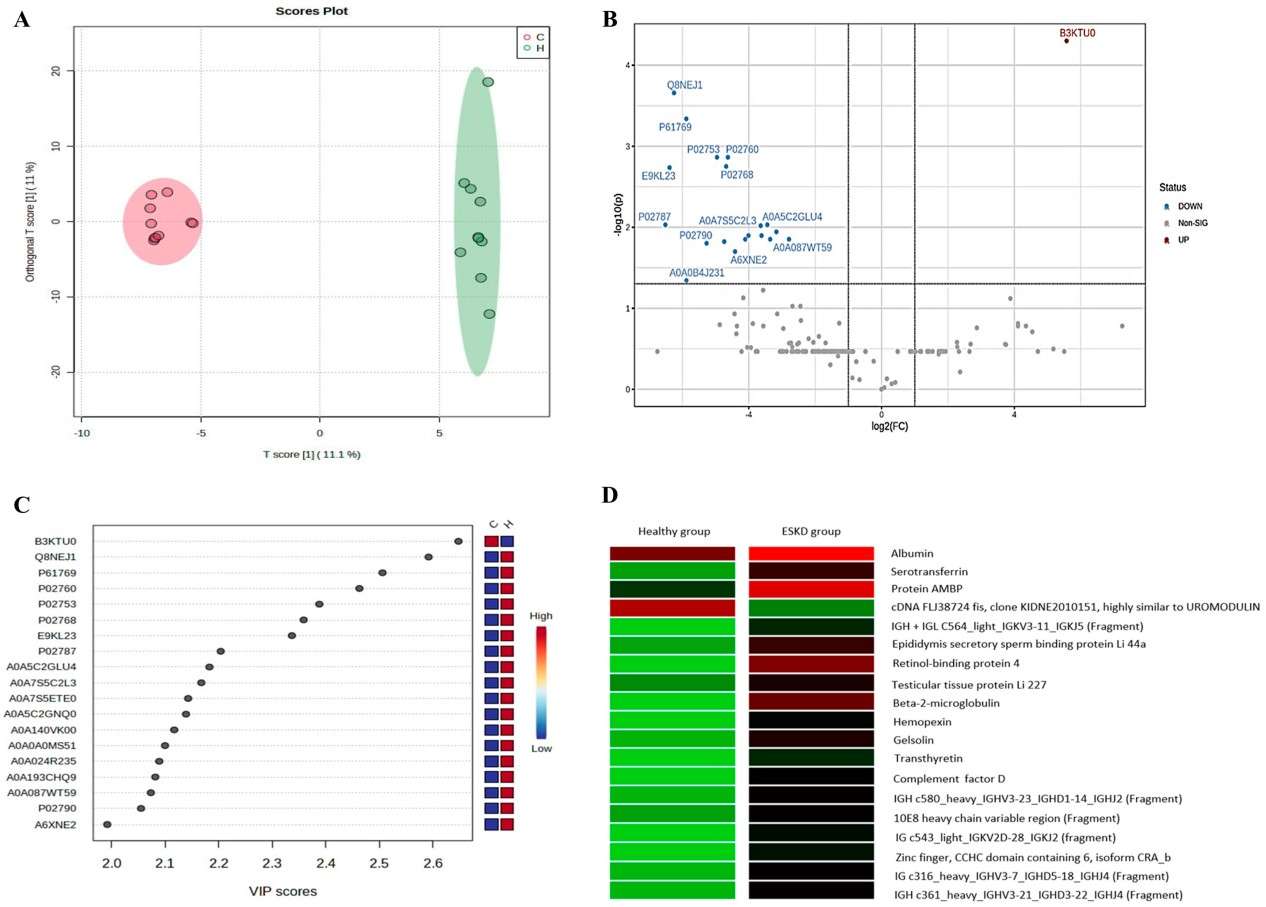
Advanced Quantitative Proteomics Platforms for High-Depth Urinary Analysis
Data-Independent Acquisition (DIA)
DIA collects fragment-ion data for all precursor ions systematically. This eliminates stochastic precursor selection and improves quantification stability. DIA resolves complex urine matrices with high confidence. The method supports biomarker discovery, pathway profiling, and differential proteome analysis across large cohorts.
DIA libraries derived from deep urinary datasets enable sensitive peptide identification. They also facilitate standardisation across instruments and laboratories.
4D-DIA and dia-PASEF
4D-DIA and dia-PASEF incorporate trapped ion mobility spectrometry. This separates peptides based on mobility, mass, retention time, and fragmentation behaviour. The four-dimensional dataset improves analytical resolution and reduces interference.
The increased sequencing speed benefits discovery-driven projects. The higher sensitivity enables the detection of ultra-low-abundance urinary proteins related to inflammation, fibrosis, or metabolic dysfunction.
Targeted Proteomics and PRM-PASEF
Targeted proteomics offers high-accuracy quantification for predefined biomarker panels. Parallel Reaction Monitoring (PRM) combined with PASEF enhances selectivity. The method provides absolute quantification when paired with stable isotope–labelled standards.
PRM-PASEF delivers robust quantification for signalling molecules, transport proteins, renal injury markers, and pharmacodynamic biomarkers.
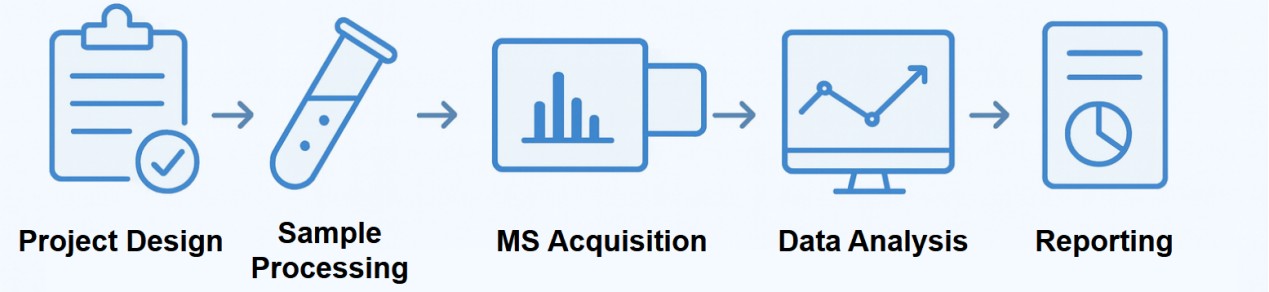
Our Comprehensive Urinary Proteomics Workflow at Creative Proteomics
- Project design: We define analytical objectives, target pathways, and sample numbers.
- Sample processing: Proteins undergo desalting, concentration, and enzymatic digestion.
- Mass spectrometry acquisition: We apply DIA, 4D-DIA, dia-PASEF, and PRM-PASEF depending on study goals.
- Data analysis: Our bioinformatics team performs peptide identification, quantitative normalization, pathway mapping, and biomarker scoring.
- Reporting: Clients receive a detailed scientific report with analytical parameters, statistical outputs, biological interpretation, and study recommendations.
Applications of Urinary Proteomics
- Kidney diseases: Detection of glomerular injury, tubular dysfunction, and fibrotic progression.
- Metabolic disorders: Profiling of diabetic nephropathy, obesity-related inflammation, and metabolic syndrome.
- Oncology: Identification of tumor-derived proteins for bladder cancer, prostate cancer, and renal carcinoma.
- Cardiovascular disease: Monitoring of endothelial dysfunction and oxidative stress markers.
- Neurological disorders: Assessment of neuroinflammatory and neurodegenerative processes reflected in urinary proteins.
- Drug development: Evaluation of pharmacodynamic biomarkers, toxicity indicators, and target engagement.